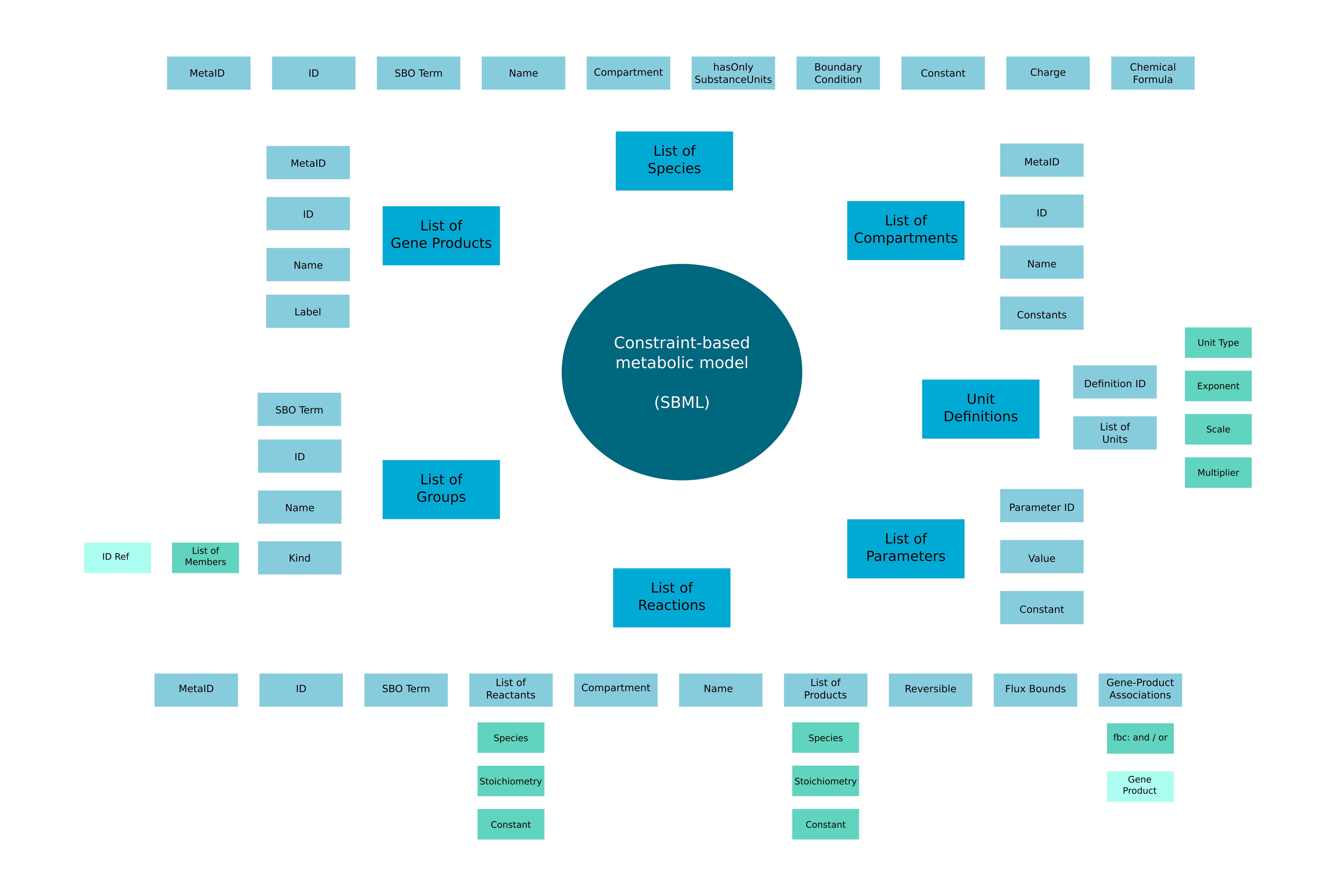
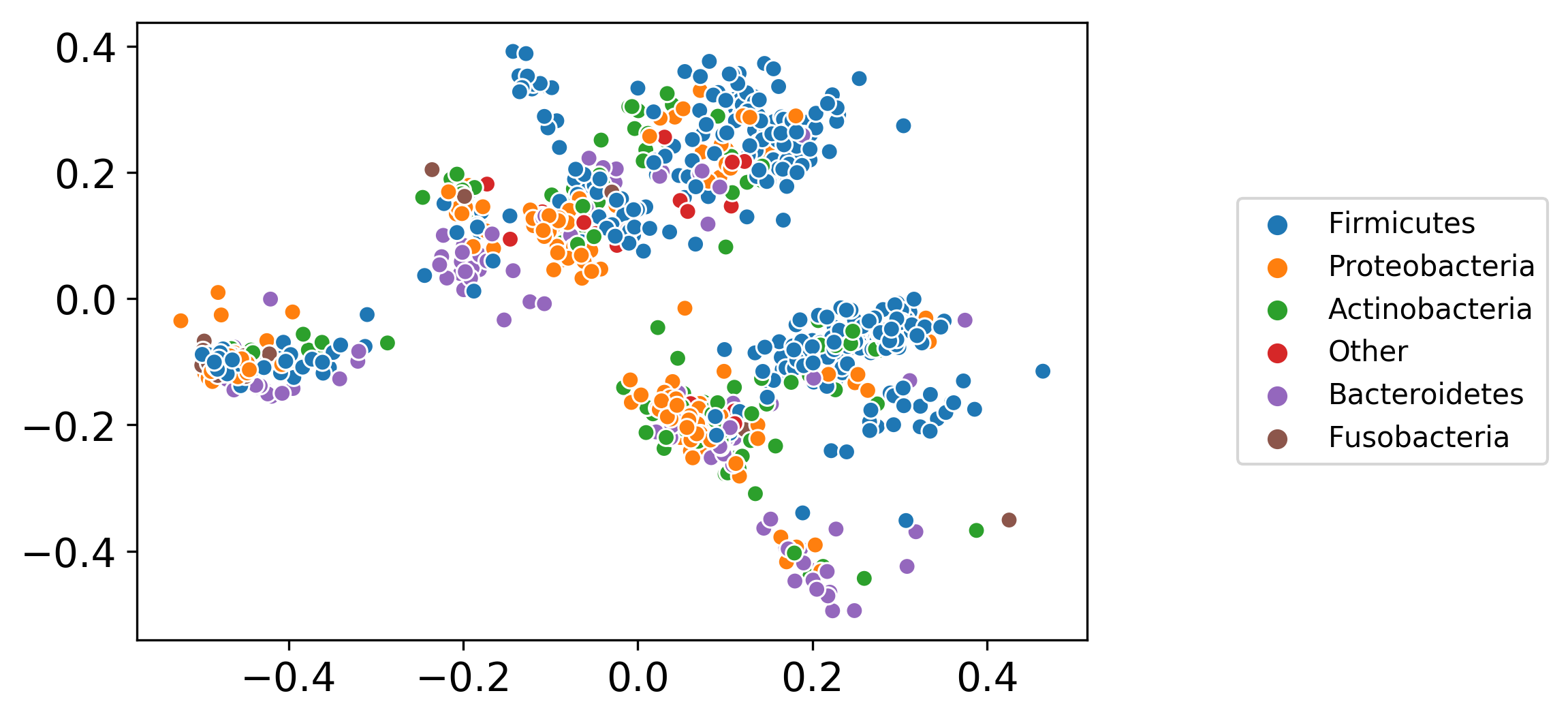
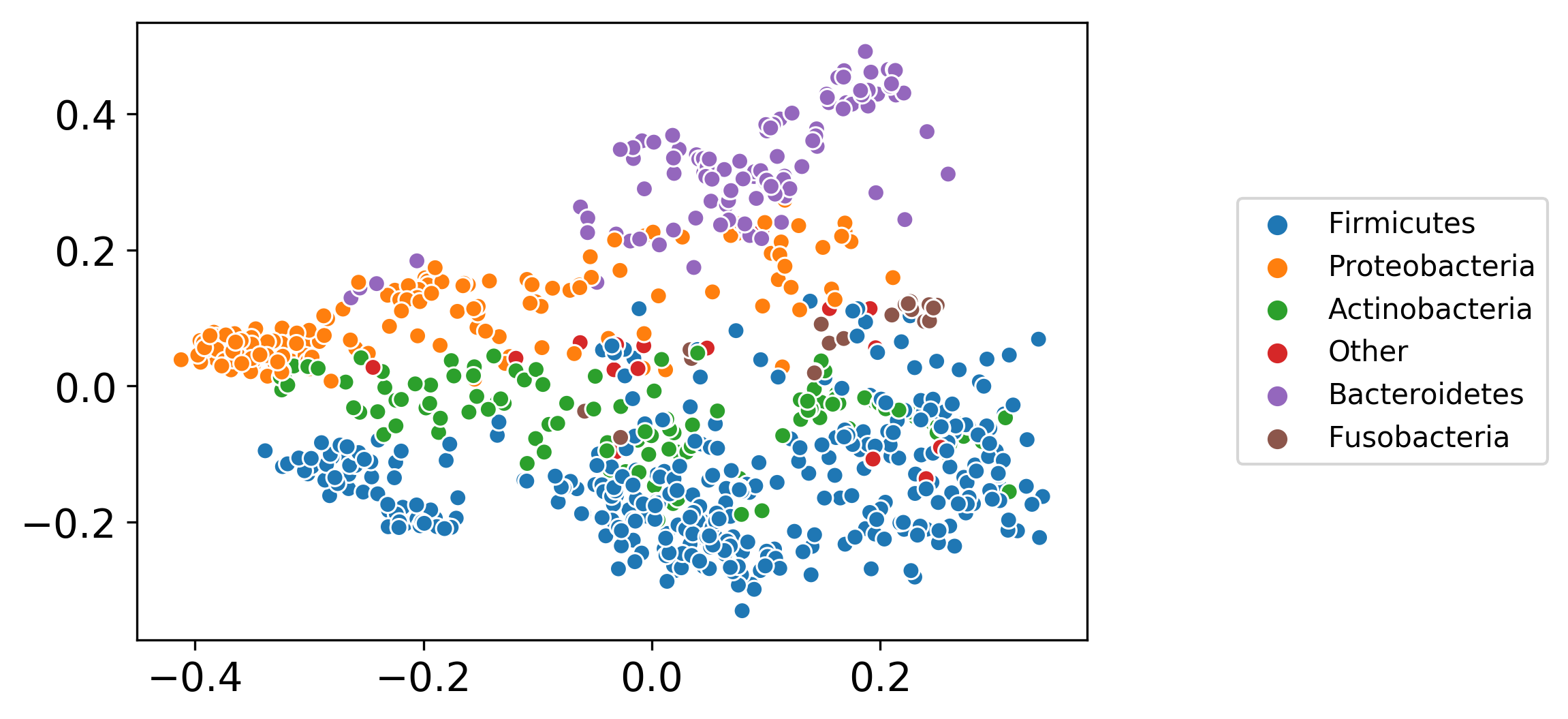
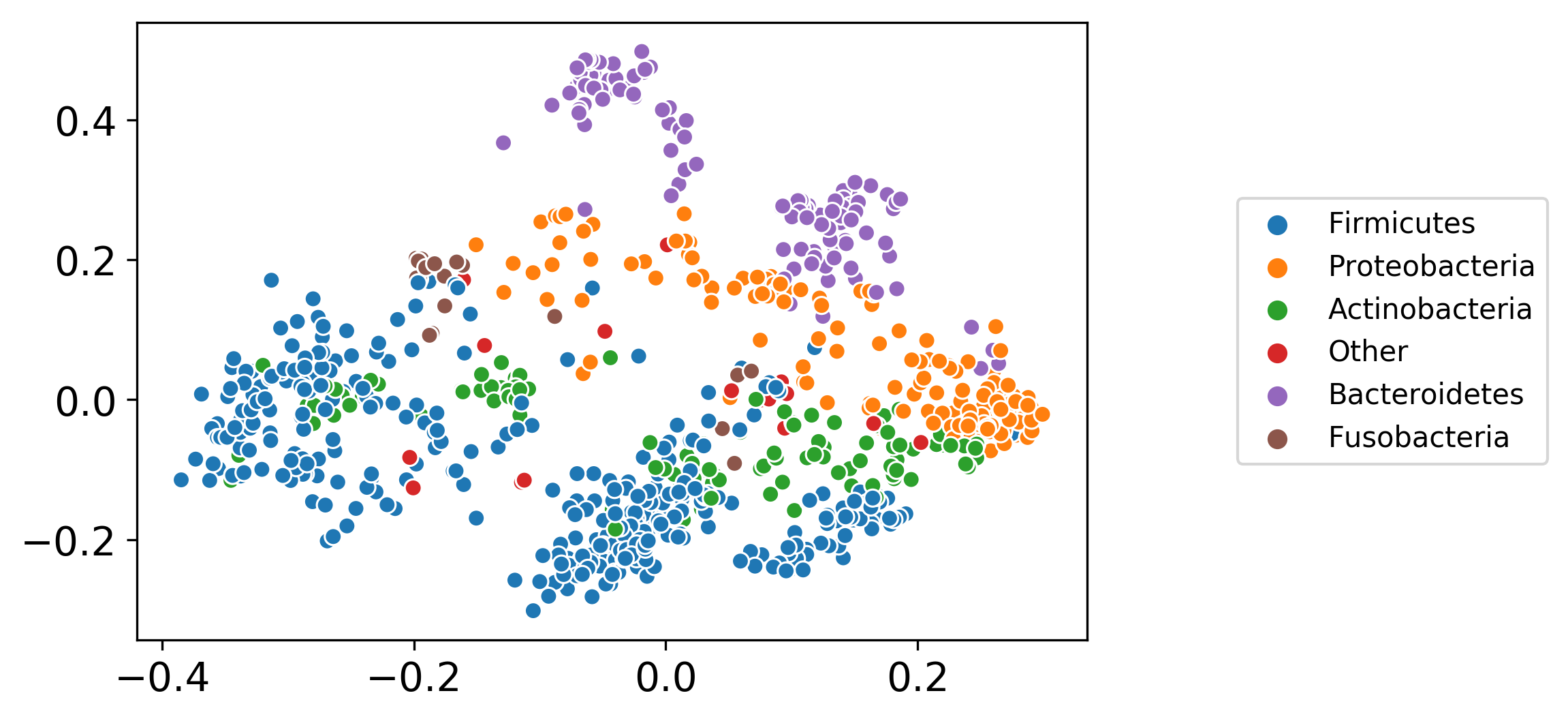
Background: Due to algorithmic advancements and to the availability of experimental datasets, large collections of genome-scale metabolic models (GSMM) can nowadays be generated automatically. Nevertheless, few tools are available to efficiently analyze such large sets of models, for example to study the link between genetic and metabolic heterogeneity. Machine Learning (ML) algorithms use the distance between data points to find patterns in large datasets. A method to determine distance between genome-scale metabolic models was thus necessary to apply ML to large model sets. We address this issue considering three levels of model representation, and defining for each of them a different distance metric: Jaccard metric for metabolic reconstructions, graph kernels for network graph topology and cosine similarity between flux distributions for constraint-based models. We employed two benchmark datasets, each containing hundreds of metabolic models, to compare the different metrics: the first is composed of 100 human genome-scale models developed from proteomics data of four different cancer tissues, while the second contains more than 800 models of bacterial species inhabiting the human gut and was developed from metagenomic data.
Results: Metrics based on the overlap of reactions content (Jaccard) and on network similarity (graph kernels) achieve remarkably similar performances in clustering and classification tasks. Phylogenetic trees built on these two metrics have the same distance from a reference taxonomy, even if the trees themselves are different from each other. Mantel test shows high correlation between distance matrices built with Jaccard and network similarity metrics.
Conclusions: We expand the concept of distance between metabolic models, highlighting new properties of the Jaccard metric such as its correlation with network similarity and function. We show how distance metrics enable the application of machine learning algorithms to genome-scale metabolic models, enabling efficient pattern recognition in large model sets.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}