This study revealed a number of quantitative aberrations, discrepancies, and findings that deem further study and could help in better assessing the epidemiological characteristics of the current COVID-19 outbreak using geolocated tweets as a proxy indicator for community attention to disease outbreaks, with possible insights related to disease transmission trends.
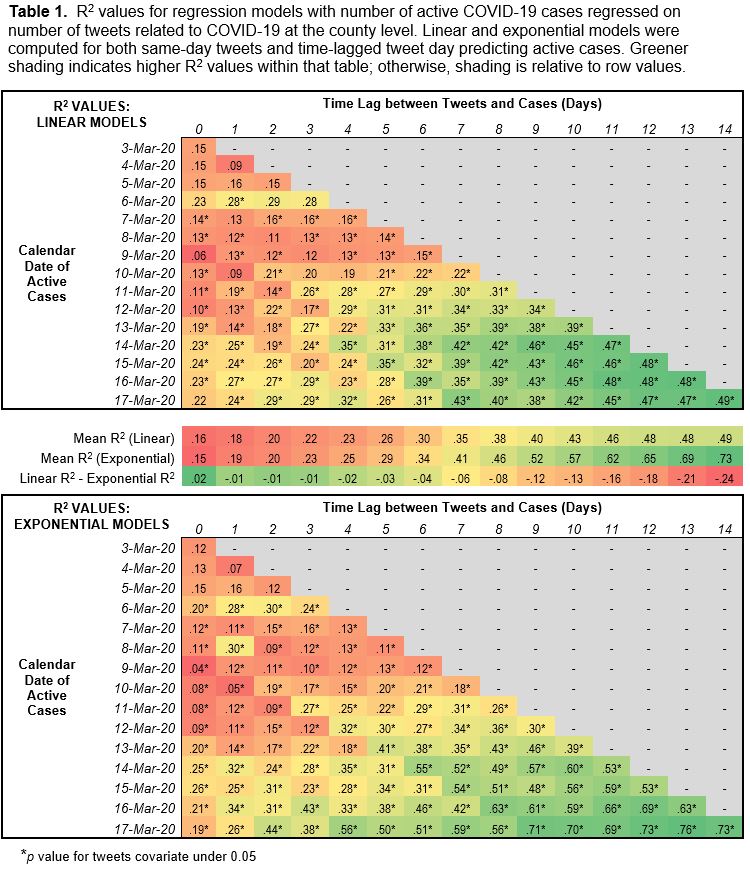
Analysis of county-level data in the United States also suggested a time lag between social media posts and predicted COVID-19 cases. In this study, posts exhibited much better fit of active cases as the time gap between posts and cases increased, especially in exponential models. The reason for this discrepancy may be that social media users are responding to COVID-19 news coverage and perceived risk, though the actual disease burden based on case counts may not be reported until later, which could also be impacted by the availability and speed of testing.
Analysis of the areas for the five most populated cities in the United States revealed some consistencies and some differences. All cities appeared to follow the national longitudinal trend, in which about one-third of locations interacting with the pandemic topic were doing so on March 3rd, which about doubled on March 17th. This result appears to indicate that, despite the total number of posts being correlated to local COVID-19 rates, the unique locations interacting with this issue appeared to be consistent with the evolving national concern about the pandemic.
Temporal differences were observed between New York City and Los Angeles County, wherein represented locations became more concentrated in New York City and less concentrated in Los Angeles County. As New York City exhibited extremely high COVID-19 rates in mid-March compared to the rest of the country, this result may partly be due to the dramatic effect observed on the normally-bustling area of Manhattan, as reflected in the following tweets from Manhattan on March 17th: “It was so eerie with empty streets in NYC Sunday like a science fiction movie #covid-19 #coronavirus,” “Here’s what Grand Central Station looks like at 6:30 PM as the mayor ponders whether to require New Yorkers to shelter-in-place. #coronavirus #covid_19 @ Grand Central Terminal,” and “As seen in #GrandCentral today. Normally BUSTLING throughout. So eerie. #COVID19 #coronavirus #Covid_19.” Los Angeles County exhibited the opposite trend, whereas the distribution of tweets became more dispersed between March 3rd and March 17th. Though some tweets from Los Angeles on March 17th observed the newfound lack of traffic, tweets were generally dispersed across topics that included general precautions and store/event closures, thereby indicating that a heightened degree of awareness to the pandemic’s impact reached new local communities between March 3rd and March 17th.
The cities of New York and Phoenix exhibited different clustering patterns than those for the areas of Los Angeles, Chicago, and Houston. In New York and Phoenix, clusters were generally from relatively densely populated city centers. However, in Los Angeles, Chicago, and Houston, clusters were mostly outside city centers. This difference suggests that, in some areas, people have tweeted their concerns and reactions primarily from home, whereas this was not the case for New York City and Phoenix. The similarity of the Phoenix area to New York City may be concerning, as New York City was thought to be, at this time, a national outlier with respect to COVID-19 burden. However, relatively few tweets were collected from the Phoenix area, so this similarity should be considered preliminary and should be further investigated.
Results from this study bear consistency with several published social media analysis on prior spread of infectious diseases. A 2016 study of Japanese tweets containing influenza symptoms found a time lag between the rate of tweets with forecasting words and the national influenza rate, as we found in this study [15]. A study of Korean tweets from 2016 found that tweets with keywords related to Middle East respiratory syndrome (MERS) were more predictive of the Korean quarantine rate as the time lag increased, but less predictive of laboratory-confirmed cases [16]. Finally, a 2010 study of English-language tweets about the H1N1 pandemic found that tweets which were automatically coded as indicative of personal disease experience, based on keywords, exhibited high correlation with personal disease experience after manual verification [17].
Throughout the COVID-19 crisis, maps have been popularly used to describe the extent and distribution of the pandemic [14, 18, 19]. However, these maps have focused on the disease itself, whereas social consequences of the disease (such as social media posts) may also provide useful insights warranting the production of maps [20, 21]. Furthermore, there exist powerful geospatial and statistical methods that can applied to these data. Though the data themselves are not direct records of the disease, careful scrutiny of indirect data manifestations of COVID-19 may be able to lend insights about the disease which otherwise are impossible to obtain.
Limitations
Findings from this study are subject to a number of important limitations. Importantly, a fraction of overall posts were geolocated, which raises the possibility of sampling bias with respect to the overall tweet corpus. Furthermore, some communities and their specific demographic features may have a greater propensity to post Twitter messages, regardless of conditions experienced in any of its users’ communities. While it is possible that this error is approximately systemic, and thereby may not appreciably contribute to the discovery of spurious relationships, little analysis has been done to verify whether the proportion of posts responding to local conditions is consistent across geospatial units. Similarly, we have considered the variation in COVID-19 cases to be reflective of true variation at an artificially deflated magnitude, due to insufficient testing. However, testing initiatives of local public health bodies may have appreciably varied during the study period, potentially resulting in erroneous variation, in addition to the suspected erroneous variation in magnitude.
This study is intended to be primarily hypothesis generating, and findings from this study should be further validated in more highly controlled settings. For example, a study in a manageable set of smaller communities should seek to determine whether variation in social media data is highly predictive of community caseloads that were obtained by especially thorough testing of those communities. Such a study may also seek to assess differences in the predictive power of social media messages at different intervals from the caseload prediction time point.
{kind=link}
{kind=link}