We have generated the seed of an inventory of annotated case studies illustrating our `real world´ information need, i.e. to retrieve possible alternatives to animal experiments from the scientific knowledgebase (herein represented by PubMed/MEDLINE). Thus far, the inventory comprises only three case studies from two ICD 10 chapters (i.e. II Neoplasms and VI Diseases of the nervous system), but we plan to achieve better coverage of all ICD 10 chapters (and subcategories) which are connected to great proportions of animal experimentation (24).
During our first attempts to annotate such case studies we realized, that `similarity´ or `relatedness´ are concepts too `vague´ to distinguish research that fulfills our information need from research that doesn’t. Since we can rely on some background regarding `interference´ in the domain of intellectual property (patents), we adapted techniques employed during an `infringement analysis´ (i.e. `claim charting´, `all elements test´) to support a stringent determination of `equivalence´. Thus, only if all the `critical´ elements of a reference research project (as depicted in a PubMed abstract) are present in another research project (PubMed abstract) such research is termed `equivalent´. To include possible alternatives to animal experimentation into such stringent definition, however, elements referring to methodology are exempted.
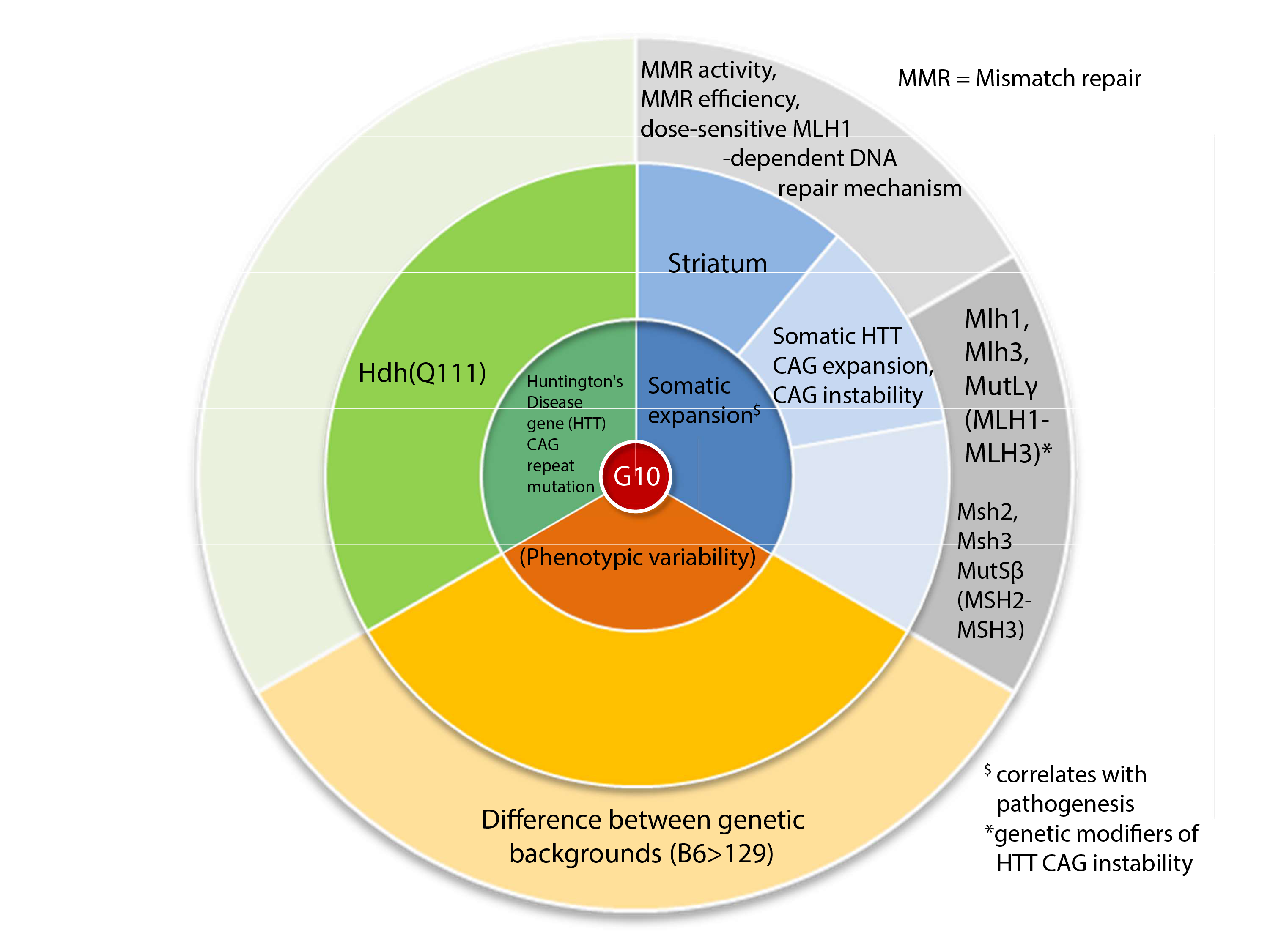
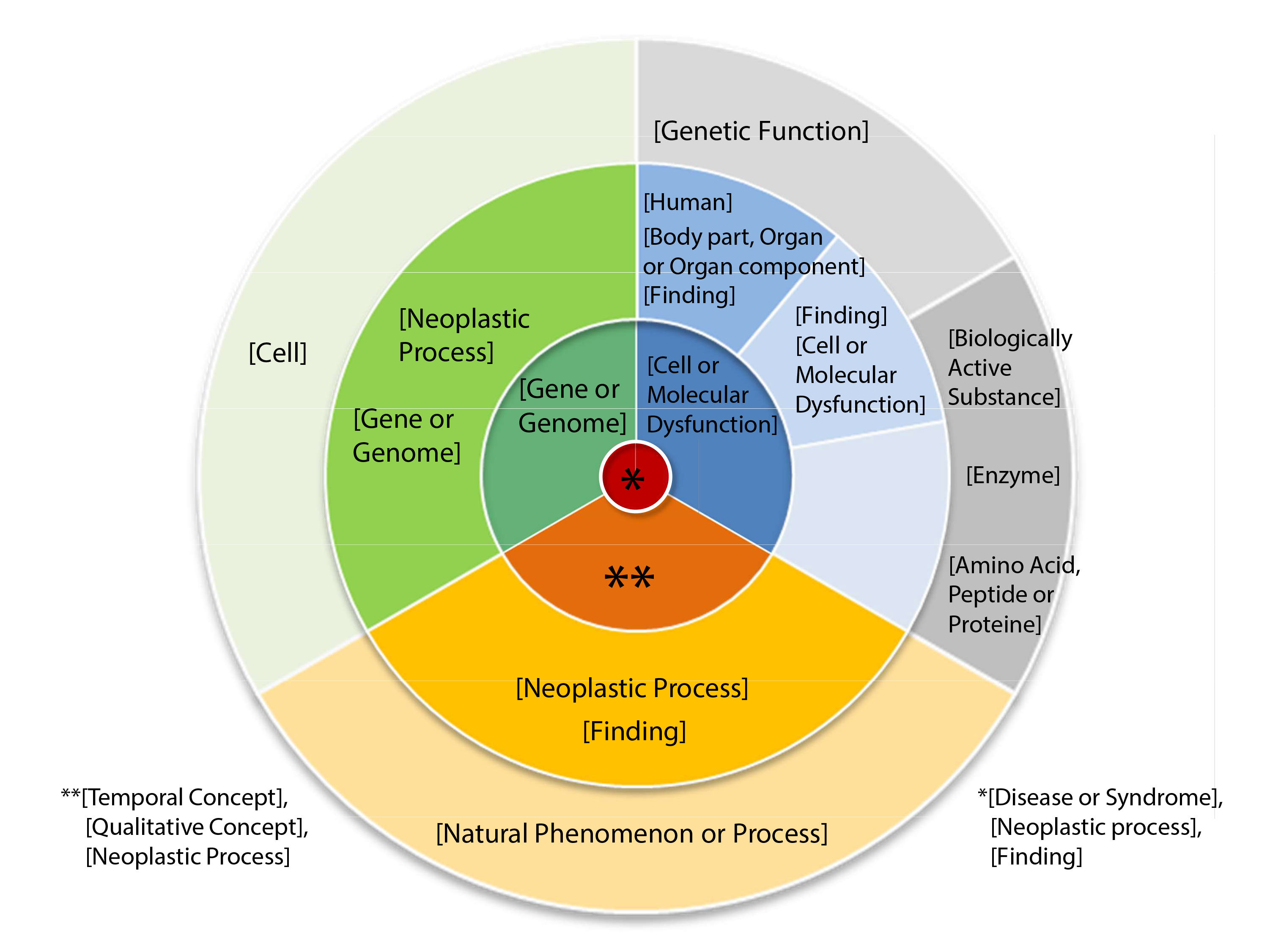
But what are `critical´ elements of research? In contrast to patents, PubMed abstracts do not provide an itemization of (scientific) claims that represent `critical´ elements. As result, such elements have to be deduced from abstracts in a way that is practicable (for researchers with average domain knowledge) and credible. Again, we built on our long-term experience in the biomedical domain and elaborated a model to support the itemization of `critical´ scientific elements in a visually guided manner, i.e. with `scientific objective charts´. Depending on the `stage of research´, the chart suggests `critical´ scientific entities that should be addressed in the abstract, e.g. “given stage: `model validation´ → question: is entity `pathogenic validity´ addressed?”. In particular, `critical´ entities describe indispensable steps towards achievement of milestones, specific for a certain stage (e.g. a `valid druggable target´ is the milestone result of `target discovery´). The actual `stage of research´ has to be determined by a trained user yet. However, we hope to inspire the elaboration of tools to achieve a full user support regarding such assessment. A possible first step into this direction will be evaluation of existing topic modeling algorithms (25). To help an adaption of such techniques to our problem, we have assigned `stages of research´ to 50% of our test publications and plan to assign such stages to all test publications of our growing corpus. Such prior-knowledge annotations then may be used to guide the topic-modeling process (semi-supervised models)(26).
Thus far, our chart is elaborated to primarily cover the stages of `model development´ and `target discovery´, since the three initial case studies reflect research of these stages only. Anyway, with more case studies to come the chart will be extended to cover later stages as well. The utility of a completed `scientific objective chart´ as means to communicate an information need was proven to be `very good´. This was exemplified with case study PMID 19735549 where such a chart, authored by the first human rater, was used to inform annotations by the second rater. Informed interrater reliability was determined to be 76% (when counting identical labels only) or 98% (when subtracting conflicting labels only). The divergence is due to test publications labeled `Limbo´ (= undecided) by only one of the raters. Our result with regard to the reproducibility of an `equivalence analysis´ is highly considerable, since the test publications prior to annotation already were prefiltered for `similarity´ by the PubMed-algorithm, making any subsequent judgement even more intricate. Thus, it is achievable to reproducibly increase the resolution of `similarity labels´ beyond the value `similar´ (`related´ → `similar´ → `equivalent´).
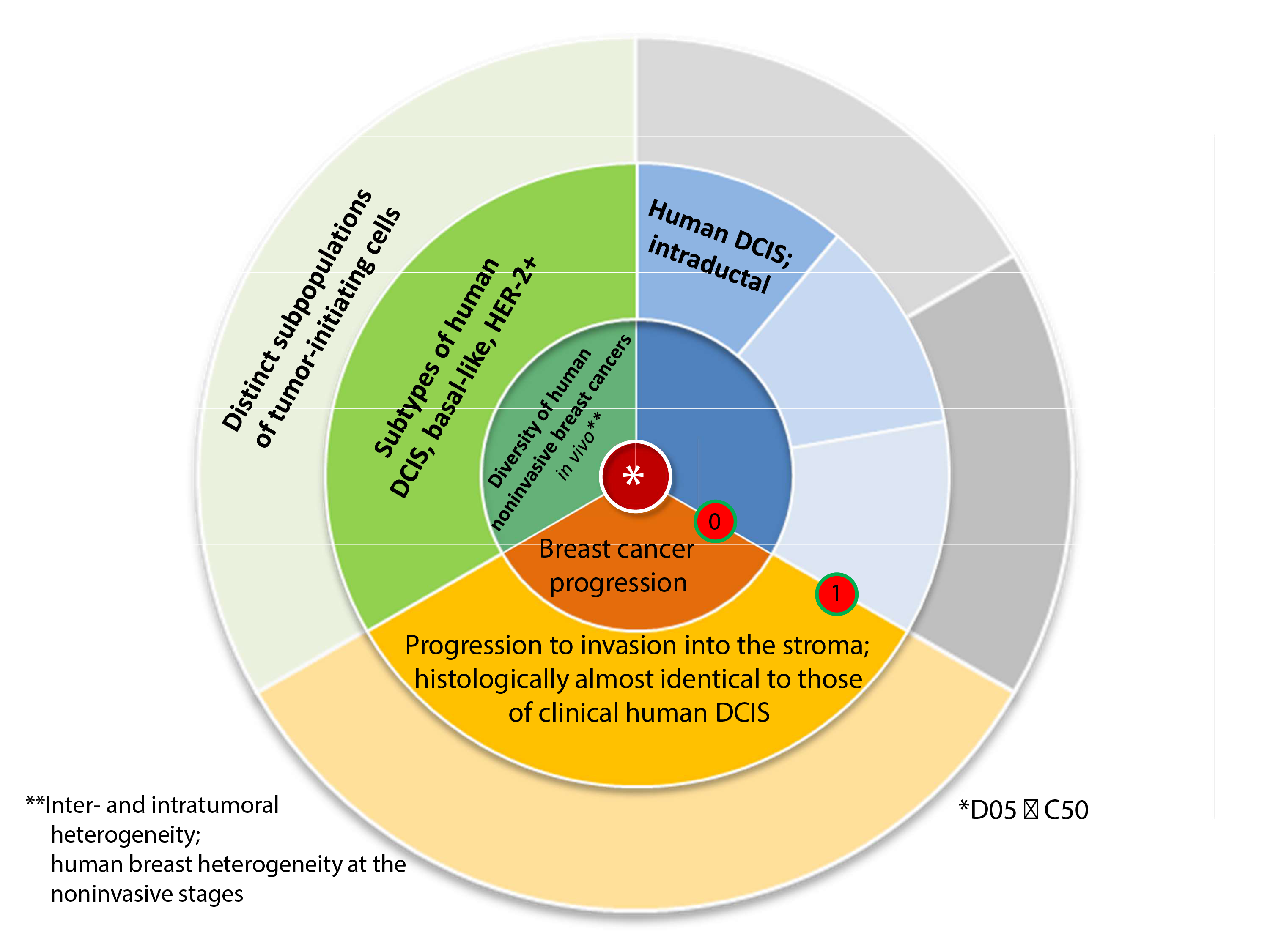
The amount of publications being judged `equivalent´ or `partly equivalent´, respectively, was quite variable among the three case studies, ranging from 11 (in 97, PMID 19735549) and 13 (in 101, PMID 24204323) to no less than 32 (in 102, PMID 21494637). Research that was judged fully `equivalent´ was present only twice in our corpus, one test publication in case studies PMID 21494637 and 24204323 each. Anyway, since only information provided in abstracts (and titles) was considered for the judgement, a subsequent inspection of full text from `partly equivalent´ publications may reveal more `equivalent´ research than that discovered at first glance. The same is true for publications judged `noteworthy´ (or `Limbo´). In such cases, the abstracts may merely contain information too insufficient for unambiguous judgement. Full text inspection then may bring clarification.
Evaluation of PubMed’s ranking algorithm revealed a clear positive selection of `equivalent´ research with most conclusive results for case study PMID 21494637 (e.g. P5 = 1, Rec50 = 0.75). Full profiles of the distributions of `equivalent´ publications after ranking by PubMed, however, revealed more complex results for `equivalents´ (see Fig. 5): thus, after positive selection of some test publications at the first ranks, the remaining `equivalents´ are distributed more or less similarly to a random distribution (PMID 21494637, parallel increases), or are clustered at much later ranks (ranks 44–63, PMID 24204323). We have screened the latter case study and found, that test publications in the early cluster (ranks 1–12) are rather `not relevant´ (5 of 6 test publications), whereas publications of the late cluster rather are `relevant´ (4 of 5 test publications). Thus, there may be a `negative co-selection´ (see below) of such test publications in some case studies. In contrast to the afore-mentioned, `equivalent´ AND `relevant´ publications are both positively selected for in case study 19735549. Thus, any occurrences of positive or negative co-selection of test publications may depend on the particular corpus `background´.
So far, we have not included test publications judged `noteworthy´ in the evaluation of ranking performance. But we will show results of a full-blown comparative evaluation of the original PubMed `similar articles´ algorithm versus an empirically calibrated version of the algorithm in a parallel publication (manuscript in preparation).
The amount of publications judged `relevant´ was in the range of ~ 10% (PMIDs 19735549, 24204323) to ~ 20% (PMID 21494637), provided that combinations of label `alternative methodology´ with labels `limbo´ OR `noteworthy´ are also deemed `relevant´. This amount is decreased, however, if only the most stringent rule is applied, i.e. `relevance´ means `equivalence´ (at least `partial equivalence´) + `alternative methodology´. Then, case study PMID 24204323 holds 7, case study PMID 21494637 holds 13 and case study PMID 19735549 9 `relevant´ publications. It is worthy to note, that the PubMed ranking algorithm in some cases seems to negatively select `relevant´ abstracts from top ranks and as result locates them at lower ranks (see Fig. 5, PMIDs 21494637 and 24204323). Thus, precision and recall at upper ranks (P20, Rec20) with regards to `relevance´ are decreased even under values expected for a random distribution. This finding - if it can be substantiated with more than 2 case studies in the future - appears plausible since `similarity´ as calculated by PubMed of course includes methodological features of any given research, with in vivo experiments being more `similar´ to other in vivo experiments than e.g. in vitro experiments. The latter, in spite of `equivalent´ scientific objectives, would be ranked lower in a respective PubMed hit list (i.e. `negative selection´).
This “shortcoming” (with regards to our information need) of PubMed is exactly what we are addressing in the SMAFIRA project1 (see section “Endnotes” for explanation of note). We aim at positive selection of `relevant´ publications and positioning at the top ranks, i.e. rank 1 to 20. To achieve this goal, however, we need a kind of `selected equivalence´ algorithm that skips any information being present in abstracts regarding methodology and focusses on information regarding scientific objective. Such selective determination of `equivalence´ may be enabled by a filtering step in text preprocessing (e.g. via MetaMap) selecting only `critical´ semantic types for downstream calculations of `equivalence´. Thus far, we have identified 15 `critical´ semantic types and have projected them onto a `master chart´. Futhermore, “zoning” of abstracts and elimination of sections that focus on methodology during preprocessing may also improve the selection of `relevant´ publications in the hitlist, by reversing any `negative selection´ due to alternative methodology (27). We will use the SMAFIRA-c corpus to further evaluate such ideas.
Anyway, there may be completely different approaches to identify `alternatives to animal experiments´ in a `database-wide´, i.e. whole PubMed/MEDLINE, manner. We therefore provide our growing SMAFIRA-c corpus to the community, hoping it will be utilized to inspire such approaches.
{kind=link}
{kind=link}
{kind=link}