This study complied with all relevant ethical regulations and was approved by the UCSF Institutional Review Board (13-12587, 17-22324, 17-23196, 18-24633). As part of routine clinical practice at UCSF, all patients included in this study signed an informed consent waiver to contribute de-identified data to scientific research projects.
Nucleic acid extraction for DNA methylation profiling, whole exome sequencing, or bulk RNA sequencing
DNA and RNA were isolated from cell lines, human samples, or mouse xenografts using the All-Prep Universal Kit (#80224, QIAGEN). For fresh frozen human samples or mouse xenografts, specimens were thawed in RLT Plus Buffer with beta-mercaptoethanol. Formalin fixed paraffin embedded tissue was de-paraffinized. All tumor or tissue samples were mechanically lysed using a TissueLyser II (QIAGEN) with stainless steel beads at 30 Hz for 90 seconds. QiaCubes were used for standardized automated nucleic acid extraction per the manufacturer’s protocol. For cell line samples, pellets were directly lysed in RLT Plus buffer with beta-mercaptoethanol. RNA quality was assessed by chip-based electrophoresis on a BioAnalyzer 2100 using the RNA 6000 Nano Kit (#5067-1511, Agilent Technologies), and clean-up was performed as needed using the RNeasy kit (QIAGEN). DNA quality was assessed by spectrophotometry, and clean-up was performed as needed using DNA precipitation. Only samples with high-quality DNA (A260/280>1.8, A260/230>1.6) and/or RNA (RIN>8) were used for DNA methylation profiling, whole exome sequencing, or bulk RNA sequencing.
DNA methylation profiling and analysis
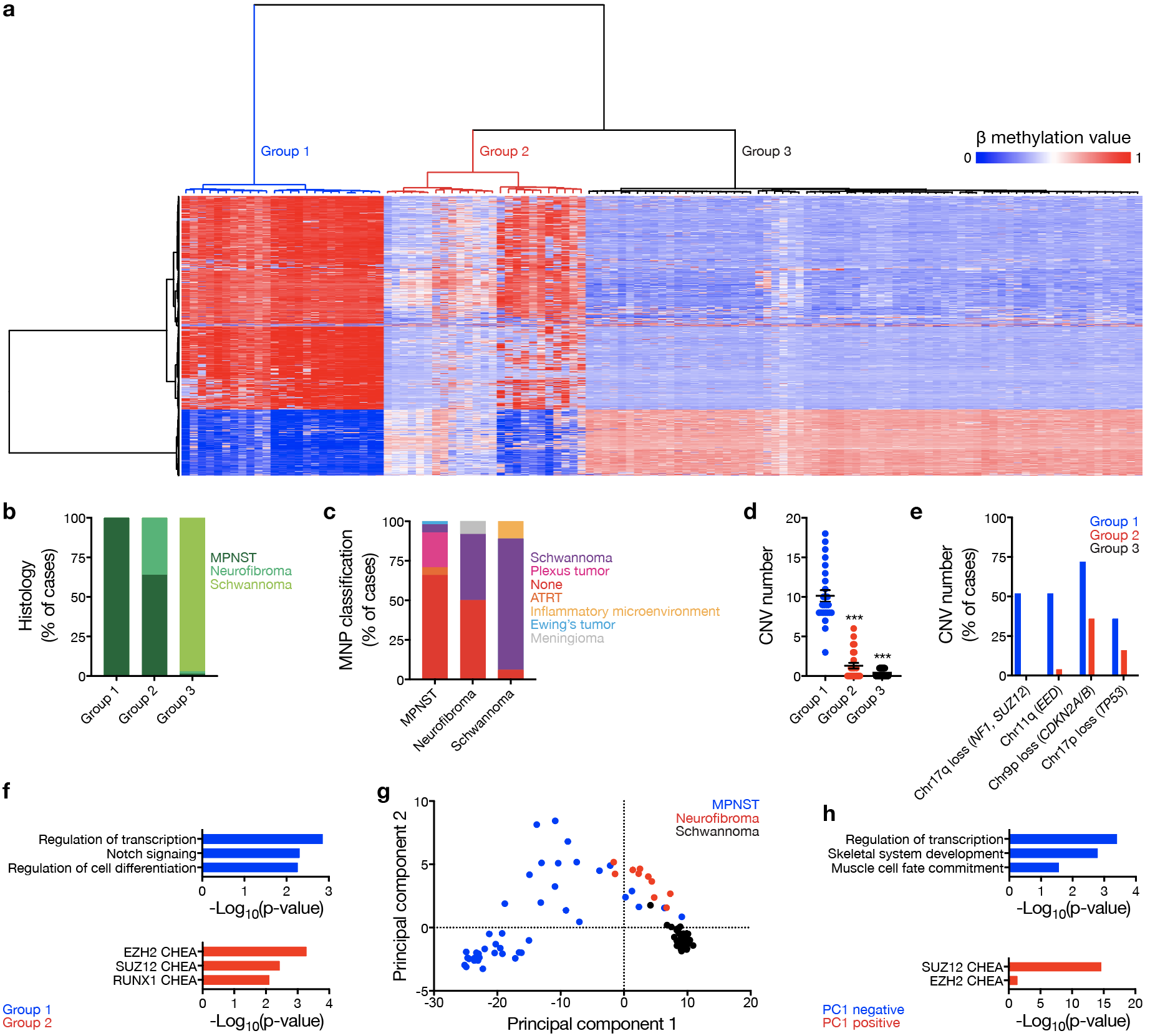
Genomic DNA from human tumors were processed for methylation analysis using the Illumina Methylation EPIC Beadchip (#WG-317-1003, Illumina) according to the manufacturer’s instructions. Preprocessing and normalization were performed in R using the minfi Bioconductor package36,37. Only probes with detection p<0.05 in all samples were included for further analysis. Data were normalized using functional normalization37. Probes were filtered based on the following criteria: (i) removal of probes mapping to the X or Y chromosomes, (ii) removal of probes containing a common single nucleotide polymorphism (SNP) within the targeted CpG site or on an adjacent basepair, and (iii) removal of probes not mapping uniquely to the hg19 human reference genome. DNA methylation-based molecular neuropathology brain tumor classification13 or CNV estimation13 were performed as previously described.
Whole exome sequencing and analysis
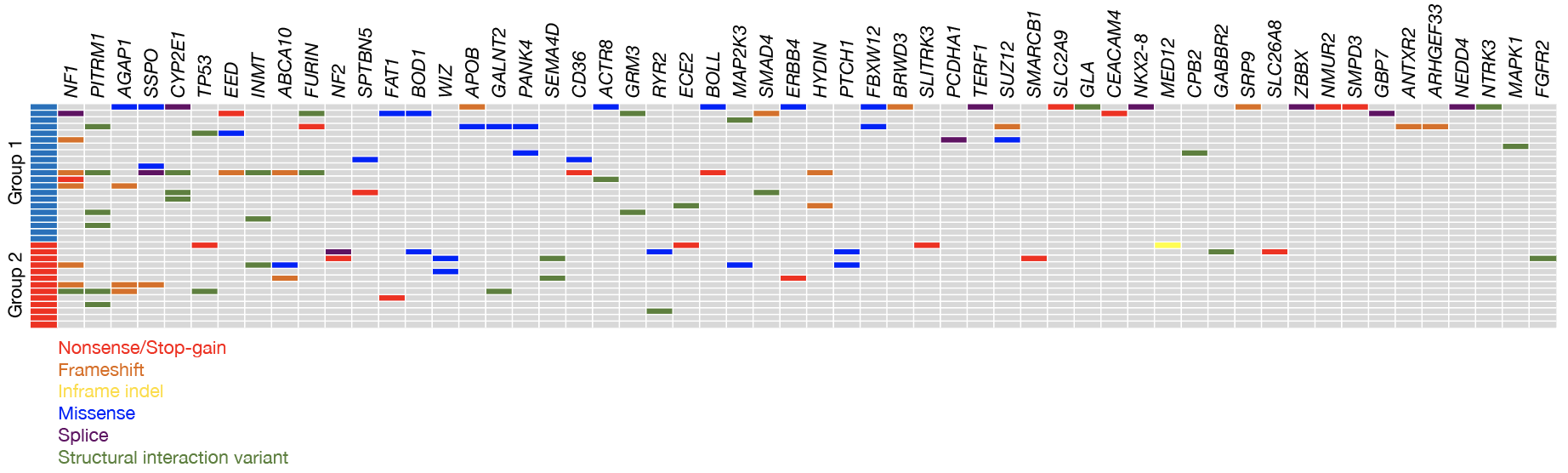
Library preparation, exome capture, and sequencing were performed at the Institute for Human Genetics at UCSF. Sequencing libraries were prepared using the Kapa Hyper Prep Kit (#07962312001, Roche) and exome capture was performed using the Nimblegen SeqCap EZ Human Exome Kit v3.0 (Roche). Paired end sequencing with read length 100 base pairs was performed on an Illumina HiSeq4000. Whole exome data were analyzed following the Genome Analysis Toolkit (GATK) best practices38,39. Raw FASTQ files were aligned to the reference genome with Bowtie240. Only uniquely aligned reads were included for further processing using the Genome Analysis Toolkit to carry out de-duplication, local realignment, and base quality score recalibration. Alignment quality metrics and header information were determined using the Picard suite (http://broadinstitute.github.io/picard/). Somatic variants (point mutations, small indels) were identified from matched tumor-normal samples (n=15) and using a panel of normal (PoN) samples with Mutect2, per GATK best practices, when a matched normal sample was not available (n=19). Variants were annotated using Snpeff41 and were further filtered to include only those marked as high/moderate/low priority, only those occurring in protein coding or splice site locations, and only those meeting the following hard filters: (i) >5 reads in tumor compared to normal samples, (ii) >10% variant reads in tumor, and (iii) >90% reference reads in normal. The full list of parameters and filters can be found in the headers of the VCF files that will be deposited in GEO.
RNA sequencing
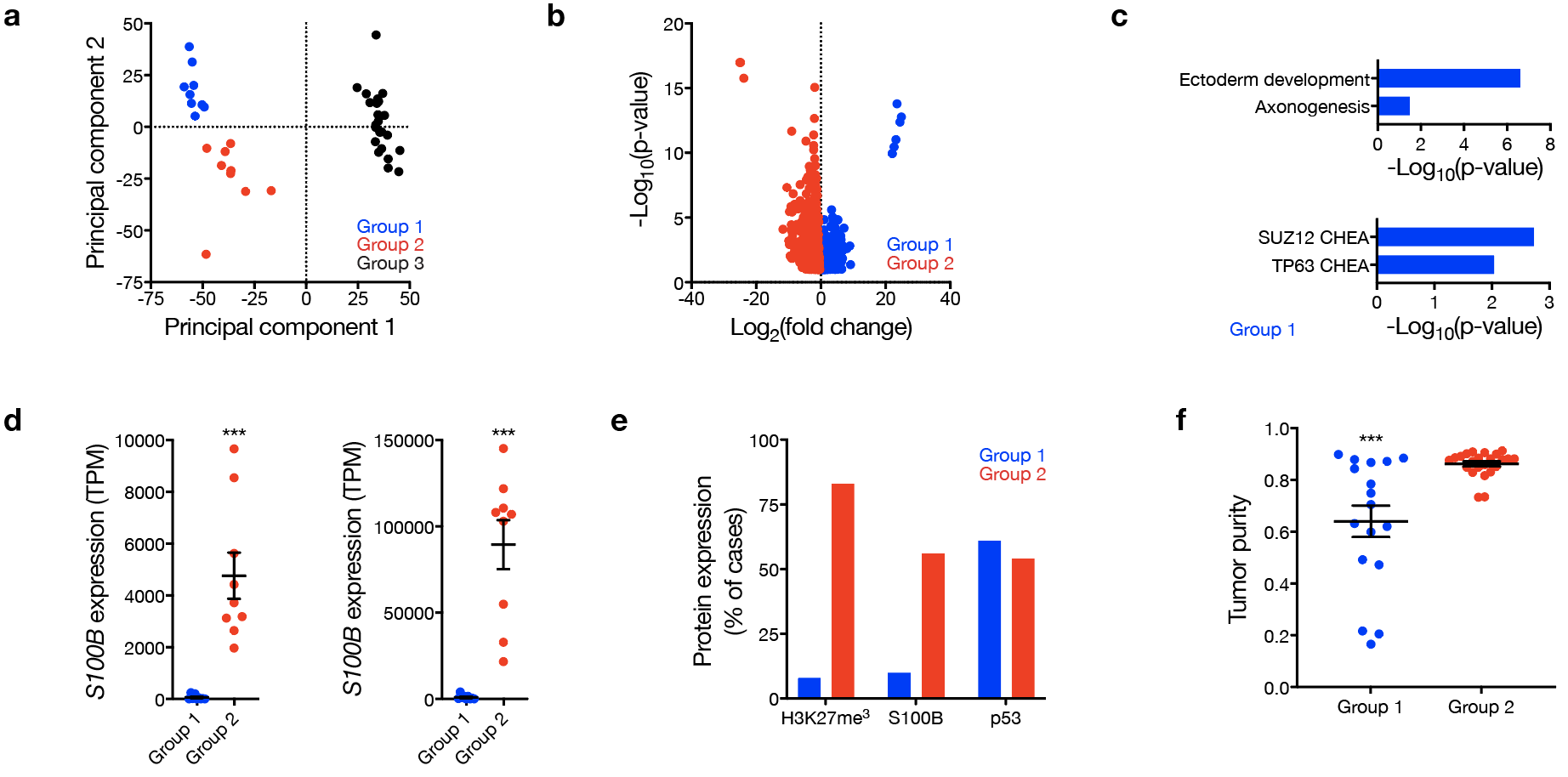
Library preparation was performed using the TruSeq RNA Library Prep Kit v2 (#RS-122- 2001, Illumina) and 50 bp single end reads were sequenced on an Illumina HiSeq 2500 or NovaSeq to a minimum depth of 25M reads per sample at Medgenome, Inc. Quality control of FASTQ files was performed with FASTQC, and after trimming of adapter sequences, reads were filtered to remove bases that did not have an average quality score of 20 within a sliding window across 4 bases (http://www.bioinformatics.babraham.ac.uk/projects/fastqc/). Reads were mapped to the appropriate reference genome (hg19 or mm10) using HISAT2 with default parameters42. Transcript abundance estimation in transcripts per million (TPM) and differential expression analysis were performed using DESeq243. Differentially expressed transcripts with an adjusted p-value<0.1 were identified and filtered based on an expression cutoff (TPM>1) and a fold change threshold (log2FC>1) to prioritize biologically relevant gene sets. Clustering dendrograms and heatmaps were generated in R using TPM values and plotted as normalized row expression values with the heatmaps.2 function.
Immunohistochemistry (IHC)
IHC was performed as previously described44 using formalin-fixed, paraffin-embedded tissue sections from tumor resection specimens on a combination of whole slide sections or tissue microarrays using the following primary antibodies: H3K27me3 (Cell Signaling Technology, #9733, clone C36B11, 1:50 dilution), SOX10 (Cell Marque, #383R-1, clone EP268, 1:50 dilution), S100B (Ventana, #760-2523, 1:2 dilution), or p53 (Dako, #GA61661-2, clone DO-7, 1:50 dilution). All IHC was performed on a Ventana Benchmark XT automated stainer (Roche) using standard techniques. IHC studies that were previously performed as part of clinical diagnostic workup, or stains obtained as part of prior research studies were reviewed for protein expression concordance44. For quantitative analysis, percent staining for H3K27me3, SOX10, or S100B was estimated as the percentage of positive tumor cells on available stained tissue.
Single-nuclear or single-cell RNA sequencing and analysis
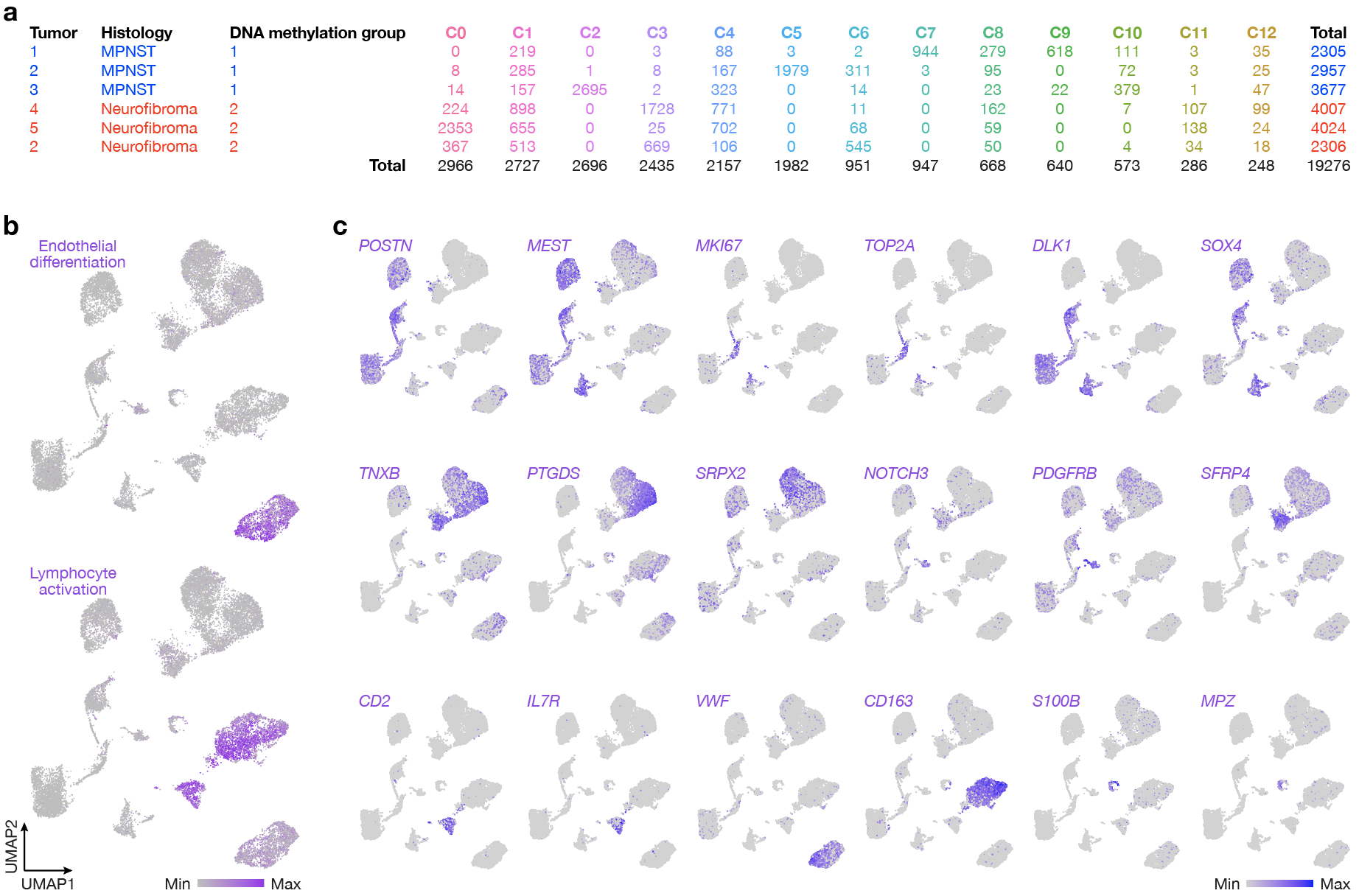
Frozen human neurofibroma or MPNST resection specimens were thawed on ice, minced with sterile razor blades, and mechanically dounced on ice in cell lysis nuclei extraction buffer until all macroscopically visible tissue dissolved into suspension. Cell suspensions were filtered through a 50 mm filter, centrifuged at 500g for 5 minutes at 4 degrees Celsius, and resuspended in 0.1% BSA in PBS. Nuclei were stained using DAPI (#D3571, Thermo Fisher Scientific) and counted. A total of 10,000 nuclei were loaded per single-nuclei RNA sequencing sample. For MPNST mouse xenograft single-cell RNA sequencing, tumors were minced with sterile razor blades and enzymatically dissociated with papain (#LS003, Worthington) at 37 degrees Celsius for 45 minutes. Samples were centrifuged at 500g for 5 minutes, resuspended in RBC lysis buffer (#00-4300-54, eBioscience), incubated for 10 minutes at room temperature, and resuspended in 5% FBS in PBS. Cell suspensions were serially filtered through 70 mm and 40 mm filters before being resuspended again in 5% FBS in PBS for manual cell counting using a hemacytometer. For cell culture single-cell RNA sequencing, cells were trypsinized and resuspended in 0.04% BSA in PBS before manual cell counting using a hemacytometer. A total of 10,000 cells were loaded per single-cell RNA sequencing sample.
Single-nuclei or single-cell RNA sequencing was performed using the Chromium Single Cell 3’ Library & Gel Bead Kit v3.1 on a 10x Chromium controller (10X Genomics) using the manufacturer recommended default protocol and settings. Samples were sequenced on an Illumina NovaSeq at the UCSF Center for Advanced Technology, and the resulting FASTQ files were processed using the CellRanger analysis suite (https://github.com/10XGenomics/cellranger) for alignment to the hg38 reference genome, identification of empty droplets, and determination of a count threshold. All downstream analyses were performed in Seurat (https://satijalab.org/seurat/) using the default pipeline. In brief, data were empirically filtered on a per sample basis to remove outliers with regard to gene count, UMI count, or mitochondrial genes followed by cluster identification, UMAP generation, and marker gene list generation using computed highly variable features and the top ten principal component dimensions as previously described35,45. The Schwann cell differentiation gene module (GO 0014037) and PRC2 target gene module (M8448) were downloaded from www.gsea-msigdb.org.
Cell culture, cell viability assays, and in vitro pharmacology
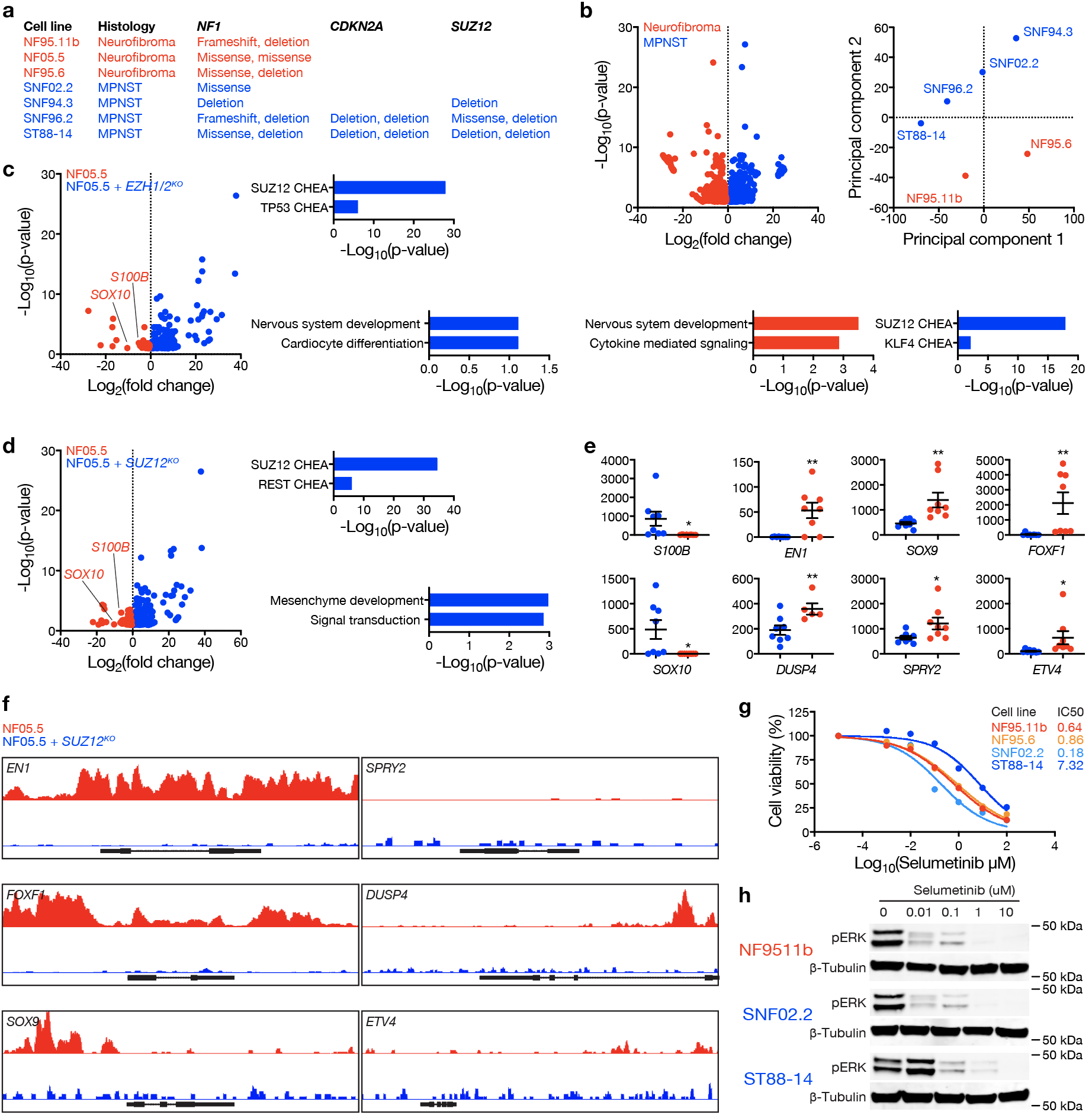
Patient-derived neurofibroma (NF95.11b, NF95.6) or MPNST (SNF02.2, SNF94.3, SNF96.2, ST88-14) cell lines46 were obtained from the Neurofibromatosis Therapeutic Acceleration Program or American Type Culture Collection. Cell lines were grown in Dulbecco’s Modified Eagle Medium (#11960069, Life Technologies) with 10% FBS and 1X Pen-Strep (#15140122, Life Technologies). Cell lines were regularly tested and verified to be mycoplasma negative (#LT07-218, Lonza). Viability assays were carried out with the CellTiter 96 Non-Radioactive Cell Proliferation Assay (#G410, Promega) and a Glomax Discovery Multimode Microplate Reader (Promega). For pharmacologic assays, cells were seeded at a density of 5,000 cells per well in a 96 well plate the night prior to treatment, after which cells were treated with drugs at the indicated concentrations for the indicated periods (or 48 hours if not indicated) prior to experimentation.
Immunoblotting
Whole cell lysates were harvested using RIPA buffer (50 mM Tris-HCl at pH 8.0, 150 mM NaCl, 0.5% Deoxycholate, 0.1% SDS, 1% IGEPAL CA-630) with fresh protease (#P8340, Sigma) and phosphatase inhibitor (#P2850, Sigma) cocktails. A total of 10-20 mg of protein was loaded into pre-cast NuPAGE electrophoresis gels (Life Technologies). Samples were separated by SDS-PAGE, transferred to nitrocellulose or PVDF membranes, and blocked in either 5% bovine serum albumin or 5% skim milk in TBS buffer for 1 hour at room temperature. Primary antibodies were incubated overnight at the indicated dilution at 4 degrees Celsius and HRP conjugated secondary antibodies were incubated for 1 hour at room temperature followed by ECL based detection on film. A minimum of 2 biologic replicates were performed for all experiments. The following antibodies were used: pERK (Cell Signaling Technologies, #4370, 1:1,000 dilution), beta tubulin (Developmental Hybridoma Studies Bank, #E7, 1:10,000 dilution), pAkt (Cell Signaling Technologies, #4060, 1:1,000 dilution), pMEK (Cell Signaling Technologies, #9121, 1:1,000 dilution), pPAK (Cell Signaling Technologies, #2601, 1:1,000 dilution), Caspase-3 (Cell Signaling Technologies, #9662, 1:1,000 dilution), Caspase-7 (Cell Signaling Technologies, #9492, 1:1,000 dilution), or NF2 (Abcam, #ab88957, clone AF1G4, 1:2,000 dilution).
Quantitative reverse transcription polymerase chain reaction (qRT-PCR)
RNA was extracted from cell lines using the RNeasy Mini Kit (#74106, QIAGEN) according to manufacturer’s instructions, and cDNA was synthesized from RNA using iScript cDNA Synthesis kit (#1708891, Bio-Rad). Real-time qPCR was performed using PowerUp SYBR Green Master Mix (#A25918, Thermo Fisher Scientific) on a QuantStudio 6 Flex Real Time PCR system (Life Technologies). The following qRT-PCR primers were used: GAPDH-F (5’-GTCTCCTCTGACTTCAACAGCG-3’), GAPDH-R (5’-ACCACCCTGTTGCTGTAGCCAA-3’), SUZ12-F (5’-AGGCTGACCACGAGCTTTTC-3’), SUZ12-R (5’-GGTGCTATGAGATTCCGAGTTC-3’), EED-F (5’-GTGACGAGAACAGCAATCCAG-3’), EED-R (5’-TATCAGGGCGTTCAGTGTTTG-3’), NF2-F (5’-TTGCGAGATGAAGTGGAAAGG-3’), NF2-R (5’-CAAGAAGTGAAAGGTGACTGGTT-3’), S100B-F (5’-TGGCCCTCATCGACGTTTTC-3’), or S100B-R (5’-ATGTTCAAAGAACTCGTGGCA-3’).
CRISPRi cell line generation and genome-wide screening
Lentivirus containing pMH0001 (UCOE-SFFV-dCas9-BFP-KRAB, #85969, Addgene) was produced from transfected HEK293T cells with packaging vectors (pMD2.G #12259, Addgene, and pCMV-dR8.91, Trono Lab) following the manufacturers protocol (#MIR6605, Mirus). Neurofibroma NF95.11b cells were stably transduced to generate parental NF95.11bdCas9-KRAB-BFP cells and selected by flow cytometry using a SH800 sorter (Sony). Subsequent gene specific knockdowns were achieved by individually cloning single-guide RNA (sgRNA) protospacer sequences into the pCRISPRia-v2 vector (#84832, Addgene) between BstXI and BlpI restriction sites. All constructs were validated by Sanger sequencing of the protospacer region. The following protospacers were used: sgNTC (GTGCACCCGGCTAGGACCGG), sgSUZ12-1 (GCTGAAACGTCTTTGGAAGG), sgSUZ12-2 (GGCAGCGGGTCGGAGATCGA), sgEED-1 (GAGTCTAGAGCCACCGTCCA), sgEED-2 (GCAGGGAGCAGGTAGCTGCT), sgNF2-1 (GTCGGGACGGGACCCCTAGA), or sgNF2-2 (GGACTCCGCGCGCCTCTCAG). Lentivirus was generated as described above and cells were selected to purity using 1 mg/mL puromycin for at least 5 days.
For genome-wide CRISPRi screening, a genome-wide dual sgRNA library was constructed by cloning the top 2 on-target sgRNAs for 23,483 genes as described previously47 into the library expression vector pU6-sgRNA Ef1alpha Puro-T2A-GFP derived from pJR85 (#140095, Addgene) and modified to express a second sgRNA using the human U6 promoter. 1137 non-targeting sgRNA pairs were also included as negative controls in the screen. To generate lentiviral pools, HEK293T cells were transfected with the sgRNA library along with packaging plasmids as described, and viral supernatant was collected 72 hours following transfection. Lentiviral libraries were infected into NF95.11bdCas9-KRAB-BFP cells, cultured for 2 days following infection, selected in 1 mg/mL puromycin for 2 days, and then allowed to recover in 10% FBS in DMEM for 1 day. Infection efficiency was evaluated by measuring BFP positivity on flow cytometry, and cell pellets were subsequently frozen down at this “T0” timepoint. The screen was subsequently carried out in biologic triplicate, with cells cultured in either 1 mM selumetinib or vehicle (DMSO) control for 10 days. Cell pellets were frozen down at this “T10” timepoint and processed for sgRNA abundance library preparation using Q5 High-Fidelity DNA Polymerase (NEB) and sequenced on an Illumina NextSeq-500 as previously described48. Enrichment or depletion of sgRNA abundances were determined by down sampling trimmed sequencing reads to equivalent amounts across all samples, and then calculating the log2 ratio of sgRNA abundance in experimental conditions to sgRNA abundance in control conditions at T10, or between sequencing reads from T10 and T0 timepoints within experimental or control conditions. Statistical significance was calculated using Student’s t-test comparing replicates across conditions. sgRNAs with fewer than 100 reads at T0 were removed from subsequent analysis. Hits were selected by normalizing log2 ratios by the standard deviations of the non-targeting control sgRNAs, and genes were considered significant at a ‘threshold’ >5 calculated as the |normalized log2 ratios| * -log10(p-value) to prioritize biologically meaningful hits for mechanistic or functional investigation.
Mouse tumor xenografts and in vivo pharmacology
The study was approved by the UCSF Institutional Animal Care and Use Committee (AN174769) and all experiments were conducted in compliance with institutional and governmental regulations. Subcutaneous xenografts were performed by implanting 5 million JW23.3 MPNST xenograft cells into the flanks of 5-6 week old female NU/NU mice (Harlan Sprague Dawley). For pharmacologic experiments, mice were treated with 25 mg/kg selumetinib twice-daily by oral gavage in 0.5% methylcellulose solution with 0.2% v/v Tween-80, 100 mg/kg 1-ABT followed by 10mg/kg NVS-PAK1-1 2 hours later in 60% PEG400/40% water, or vehicle control gavaged once daily. Tumors were measured using calipers 3 times per week.
Statistical Analysis
All experiments were performed as repeated, independent biologic replicates, and statistics were derived from biologic replicates. The number of biologic replicates is indicated in each panel or figure legend. No statistical methods were used to predetermine sample sizes. Considering the rarity of MPNSTs and accounting for the number of genomic approaches used in this study, our total cohort size is similar to prior publications6–8. The clinical samples used were retrospective and non-randomized, and all samples were equally interrogated within the constraints of sufficient tissue for each analytical method. Cells and animals were randomized to experimental conditions, and no clinical, molecular, cellular, or animal data points were excluded from analysis. Unless otherwise specified, data are plotted as mean with error bars representing the standard error of the mean. The statistical tests of choice were selected based on the input data and are noted in the methods and figure legends. All statistical tests were one-sided. Where appropriate, multiple hypothesis testing corrections were performed. Statistical significance thresholds are indicated in each figure legend and exact p-values are provided when possible.
Data availability
Human tumor DNA methylation (n=119), RNA sequencing (n=41), whole exome sequencing (n=34), or single-cell RNA sequencing data (n=6) reported in this manuscript will be deposited in the NCBI Gene Expression Omnibus. Cell line RNA-sequencing (n=6), selumetinib-treated cell line RNA-sequencing (n=10), CRISPRi NF2-deficient cell line RNA-sequencing (n=4), or single-cell RNA sequencing of mouse xenograft data (n=5) reported in this manuscript will similarly be deposited in the NCBI Gene Expression Omnibus. Additional RNA-sequencing and H3K27 trimethylation ChIP sequencing data from previously reported PRC2-intact or PRC2-deficient neurofibroma cell lines is available under GSE 118185 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE118185) or GSE118183 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE118183), respectively19. The publicly available GRCh37 (hg19, https://www.ncbi.nlm.nih.gov/assembly/GCF_000001405.13/) and GRCm38 datasets (mm10, https://www.ncbi.nlm.nih.gov/assembly/GCF_000001635.20/) were used in this study.
Code availability
The open-source software, tools, and packages used for data analysis in this study, as well as the version of each program, were ImageJ (v2.1.0), R (v3.5.3 and v3.6.1), FASTQC (v0.11.9), HISAT2 (v2.1.0), featureCounts (v2.0.1), Bowtie2 (v2.3), snpEff (v5.1), Mutect2 (v4.0), picard (v2.2), cellranger (v6.1.2), Seurat R package (v3.0.1), DESeq2 (Bioconductor v3.10), minfi (Bioconductor v3.10), ConsensusClusterPlus (Bioconductor v3.10), Heatmap.2 R package (gplots v3.13), and ggplot2 (v3.3.6). No custom software, tools, or packages were used.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}