Measurement of bile acid binding in a synthetic peptide array
Training data is essential for the construction of the classification model. To generate training data, 460 4-, 5-, 6-, and 7-mer peptides were generated in a peptide array, and their bile acid binding activities were evaluated. The sequences and fluorescent intensities are shown in Table S2 and Figure S1. The fluorescence intensity of 4-mers was relatively lower than that of longer peptides (Fig. S1(A)). The observed low intensity of 4-mers in the training data may be due to the relatively low hydrophobicity of 4-mer peptides. Using the peptide array data, 150 peptides with the highest fluorescent intensities were defined as the ‘positive’ dataset, and 150 peptides with the lowest fluorescent intensities were defined as a ‘negative’ dataset for bile acid binding activity. The average fluorescence intensities of the positive and negative datasets are shown in Table 1. Since there was a significant difference between the two datasets (P < 0.001), the randomly designed peptide library contained peptides with different bile acid binding bioactivities.
Construction of predictive model and evaluation of model performance
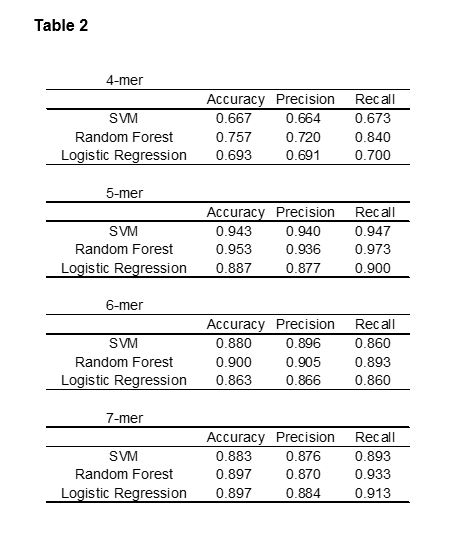
To construct the predictive model, the peptide features of 300 peptides (positive = 150, negative = 150) were calculated. For each 4-mer, 56 features were generated (28 amino acid features and 28 global features), for each 5-mer 63 (35 amino acid features and 28 global features), 6-mer 70 (42 amino acid features and 28 global features), and 7-mer 77 (49 amino acid features and 28 global features), and used as explanatory variables. Three algorithms were used to construct the predictive model (SVM, RF, LR), and the model performance was evaluated by comparing accuracy, precision, and recall. The peptides with a probability of >0.5 were designated as positive, and those with a probability of <0.5 were designated as negative for bile acid binding ability. Except for the precision scores of 5- and 7-mers, all RF scores were the highest out of the 3 tested algorithms (Table 2). RF was therefore selected for the predictive algorithm.
The scores 4-mer peptides were lower than the scores of longer peptides (Table 2). The ratio of the average fluorescence intensity of positive the dataset and that of the negative dataset was defined as the P/N intensity ratio. In Table 1, the P/N intensity ratio of 4-mers (2.67) was lower than that of longer peptides (3.63 for 5-mers, 4.11 for 6-mers, 3.87 for 7-mers). This is caused by the relatively lower overall fluorescence intensity of the 4-mer training data. The model performance was roughly corelated with the P/N intensity ratio. The reason for the poor performance is the relatively large number of FPs and FNs predicted by the acquired model when the P/N intensity ratio is low.
To investigate the importance of the input features, the variable importance was estimated according to the increase in the predictive error due to the permutation of out-of-bag data for the given variable. The importance of each of the input variables is shown in Table S3. Most of the top 10 selected features referred to global features of peptides, namely av, sd, min, max, with the exception of two specific features: residue2_Molecular_weight for 4-mers and residue1_Isoelectric_point for 7-mers. In addition, two features for 4-mers, four features for 5-mers, four features for 6-mers, and five features for 7-mers were related to the peptide isoelectric point. Similarly, five features for 4-mers, three features for 5-mers, two features for 6-mers, and two features for 7-mers were related to molecular weight. This suggests that the global peptide features are more important than the site-specific features for bile acid binding activity in peptides of 4-7 amino acids. Bile acid molecules are amphiphilic, with a hydrophobic steroid core and hydrophilic hydroxyl groups, and therefore have strong surfactant action. Since peptide binding can occur in in either direction with bile acids, site-specific peptide features may be less important.
Features referring to isoelectric point and molecular weight were among the most important in Table S3. This suggests that peptides with high isoelectric points or high molecular weights bind to strongly to bile acid. The five amino acids with the highest isoelectric points are R, K, H, P, and I20, and the top five for molecular weight are W, Y, R, F, and H21. The basic or aromatic peptides therefore have higher binding activity against bile acids. Some studies have investigated the binding mechanisms between bile acids and other compounds, such as sterols and nisin22, 23, 24, 25, and revealed that hydrophobic amino acids, especially aromatic amino acids, interact with bile acid micelles. These findings are in agreement with the top 10 features identified in Table S3.
Construction of edible peptide database and prediction of bile acid binding activities
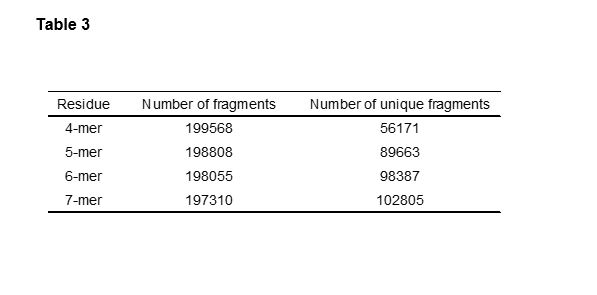
A set of 710 edible proteins were obtained from BIOPEP-UWM and digested using all available predicted protease binding sites (Table 3), resulting in 199568 4-mers, 198808 5-mers, 198055 6-mers, and 197310 7-mers. After removing duplicate sequences, the dataset contained 56171 4-mers, 89663 5-mers, 98387 6-mers, and 102805 7-mers. A total dataset of approximately 350000 peptide sequences was thus generated.
The RF model was applied to the peptide datasets, and the results are shown in Table S4. To verify the RF model, the results were sorted by the probability of being classified as positive for bile acid binding activity. Fifty peptides from the top and 50 peptides from the bottom of the probability list were synthesized and their bile acid binding activities were determined using a peptide array. The synthesized sequences are listed in Table S5, and their fluorescence intensities are shown in Figure 2. The average fluorescence intensity of positive peptides was higher than that of negative peptides (P < 0.001), indicating that the RF model could successfully predict bile acid binding activity. The details of the peptides are shown in Table S6.
Novel bile acid binding peptides from edible proteins
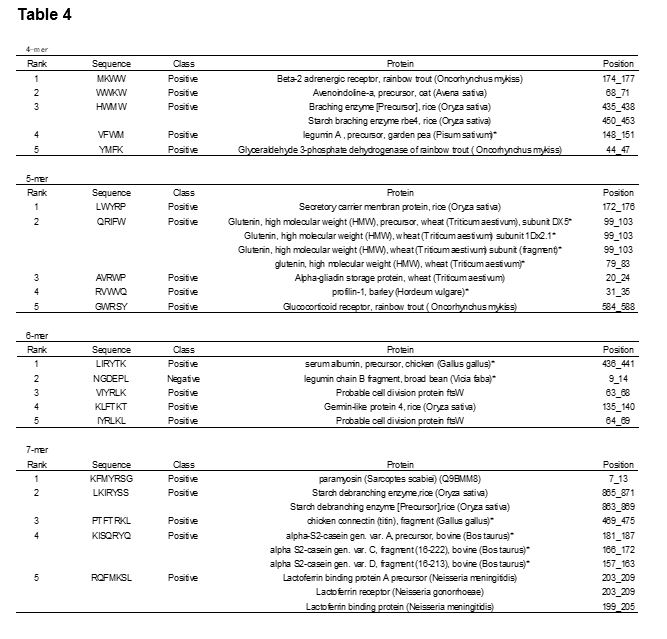
The top five peptides, ranked by fluorescence intensity in a peptide array for bile acid binding, are shown in Table 4. Seven of the peptides with the highest scores for bile acid binding activity mapped to storage proteins in the database: VFWM from legumin A (Pisum sativum)26, QRIFW from high molecular weight glutenin (Triticum aestivum)27, RVWVQ from profilin-1 (Hordeum vulgare)28, LIRYTK from serum albumin (Gallus gallus)28, NGDEPL from legumin chain B fragment (Vicia faba)29, PTFTRKL from chicken connectin (titin) fragment (Gallus gallus)28, and KISQRYQ from alpha-S2-casein (Bos taurus)28. NGDEPL was predicted to have low affinity for bile acid; however, it had a high bile acid binding activity according to the peptide array. The mechanisms underlying this apparent contradiction are unclear, but this peptide might bind stereospecifically to bile acids. Since storage proteins are favorable for the manufacture of health foods and cosmetics, these protein sources are expected to contain novel bioactive components.
Most of the predicted bioactive peptides in the present dataset were obtained by proteolysis by enzymes from plants or microorganisms, and proteolysis by gastrointestinal enzymes30. Therefore, to evaluate the utility of these peptides at the industrial scale, we examined whether the seven peptides derived from storage proteins could be generated using peptidases or proteases. As a result, KISQRYQ was predicted to generated from alpha-S2-casein (Bos taurus) with peptidyl-Lys metalloendopeptidase (Armillaria mellea neutral proteinase). Gutiez et al. had previously investigated the relationship between the autolysis caused by lactic acid bacteria and the production of angiotensin-converting enzyme (ACE)-inhibitory peptides, and reported that KISQRYQ was generated from skimmed milk (alpha-S2-casein) by Lactococcus lactis subsp. lactis IL140331. Taken together, this suggests that KISQRYQ could be a candidate bioactive peptide for health food.
In the present study, a new bioactive peptide screening method was developed based on a synthetic peptide library for bile acid binding and machine learning. A database containing peptide sequences derived from edible proteins was developed to identify peptides with features that are associated with bile acid binding. Combining these two tools, novel bile acid-binding candidate peptides have been discovered. Among the peptides with the highest predicted scores for bile acid binding activity, seven (VFWM, QRIFW, RVWVQ, LIRYTK, NGDEPL, PTFTRKL, and KISQRYQ) were derived from storage proteins. Among them, KISQRYQ was predicted to be generated from alpha-S2-casein (Bos taurus) with peptidyl-Lys metalloendopeptidase (Armillaria mellea neutral proteinase) or from skim milk with Lactococcus lactis subsp. lactis IL1403. Our novel method could successfully screen bioactive peptides, and can easily be applied to industrial applications based on whole edible proteins. The proposed approach would be useful for bile acid-binding peptides, as well for other bioactive peptides, as long as a large amount of training data could be obtained.
{kind=link}
{kind=link}
{kind=link}
{kind=link}