Site description and sample collection
Three samples were collected from oil-polluted soils (OPS), and one control soil (CS) was obtained from an old engine scrap plant in Taolin Town, Donghai County, Lianyungang City, Jiangsu Province, China. OPS sample one was obtained from a dry soil polluted with engine oil, located between latitude 34°31′2″N and 118°29′45″E, at an elevation of 60 meters above sea level. OPS sample two was collected from soil near the streaming water polluted with oil, located between latitude 34°31′21″N and 118°29′29″E, at an elevation of 56 meters above sea level.
OPS sample three was obtained from the soil of a stagnating pool of engine oil, located between latitude 34°31′23″N and 118°28′58″E, at an elevation of 62 meters above sea level. The CS sample, used as a control, was collected at a depth ranging from 0–6 cm, between latitude 34°31′20″N and 118°29′29″E, at an elevation of 60 meters above sea level. Each site was sampled in triplicate using sterile, DNAs- and RNAs-free tubes (Corning®, USA). The samples were immediately transferred to the lab for total DNA extraction and bacterial culture, while the remaining samples were stored at -80°C until further processing.
Soil hydrocarbons test
To study the petroleum hydrocarbon contents in OPS, about 10g of sample, was mixed with an appropriate amount of anhydrous sodium sulfate to dehydrate the sample. The procedures were modified from the previous study (Su et al. 2023). Briefly, the samples were transferred to the filter cartridge and 100mL of n-hexane-acetone mixed reagent (1:1) was added and extracted for 16-18h. After cooling, the extract was concentrated and purified and finally concentrated to 1ml for testing by gas chromatography GC-ECD/FID TRACE1300 (Thermo Fisher Scientific, USA). The experimental conditions were as follows: The theoretical concentration value of QC is: 1550 µ g/mL; Sample spiked quantity: 1550 µg; Blank standard: 1550ug; Standard solution No.: LH220825-01. Sample inlet temperature: 280 ℃, column oven temperature: 50 ℃ for 2 min, rise to 230 ℃ at 40 ℃/min, and then rise to 300 ℃ at 20 ℃/min for 5 min, chromatographic column model: select mineral oil, detector temperature: 300 ℃.
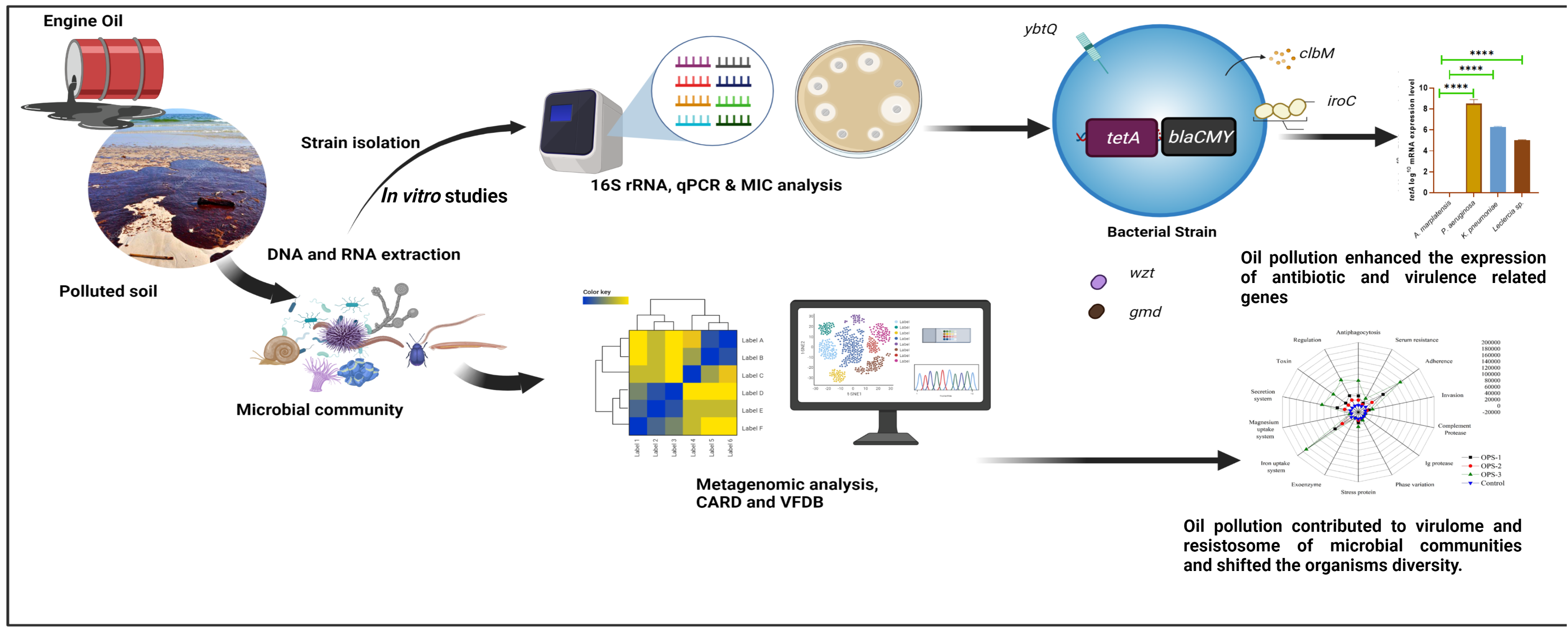
Total DNA extraction, library construction and Shotgun metagenomic sequencing
DNA from the soil samples (OPS1, OPS2, OPS3, and CS) were extracted and purified using the E.Z.N.A. Soil DNA Kit D5625 (Omega Bio-Tek, Inc., USA) as per the manufacturer's instructions. The protocol was modified according to a previous report (Bao et al. 2017). Briefly, 5 grams of soil was placed in a 50 ml sterile polypropylene tube and resuspended in 10 ml Buffer SLX Plus PD09 with 5 g of glass beads (0.1 mm). The mixture was then agitated in a mini-bead beater, thrice for 60 seconds each time. After that 1 ml Buffer, DS was added, the samples were vortexed and incubated at 70°C for 10 min followed by 90°C incubation for 5 min. The quality check of extracted DNA was performed using 1% agarose gel electrophoresis and quantified using the Nanodrop 2000 (Thermo Fisher Scientific, USA). The three OPS and CS were sequenced and analyzed Mojorbio company (Majorbio, Shanghai, China) for shotgun metagenomic sequencing. Briefly, 40 ng of DNA were used to prepare the libraries with a Nextera DNA kit (Illumina, USA), as per manufacturer’s instructions. Afterward, the adapters were added, libraries diluted and pair-end sequenced for 300 cycles using a NovaSeq Reagent/HiSeqX system (Illumina, USA).
Metagenomic analysis
For raw sequence analysis, multiple samples were mixed and sequenced in parallel, and the sequences in each sample were labeled with an Index tag sequence indicating each sample. The data of each sample are distinguished according to the Index sequence, and the extracted data is saved in fastq format. To perform data quality control the low-quality and N-containing reads were trimmed. Prodigalv2.6.3 (Hyatt et al. 2010) was used for gene prediction. Genes whose length is greater than or equal to 100bp and translated into amino acid sequences.
The predicted gene sequences of all samples were analyzed by CD-HIT software (Fu et al. 2012) for clustering, each class taking the longest gene as a representative sequence to construct a non-redundant gene set. To calculate gene abundance, we used SOAP aligner software to compare the high-quality reads of each sample with the non-redundant gene (NR) set and count the abundance information of the genes in each sample. NR species annotation from NR database using Amino acid sequence database of non-redundant proteins, including SwissProt, PIR (Protein Information Resource), PRF (Protein Research Foundation), PDB (Protein Data Bank) protein database non-redundant data and protein data translated from GenBank and RefSeq CDS data. To compare the non-redundant gene set with the NR database (comparison type: BLASTP), DIAMOND software (Buchfink et al. 2015) was used and passed the corresponding classification of the NR database. In the taxonomic information database, we compared the gene abundance of species in each sample at each taxonomic level of domain, kingdom, phylum, class, order, family, genus, and species in order to construct the abundance profile at the corresponding taxonomic level. Comprehensive Antibiotic Resistance Database (CARD) was used to analyze the antibiotic resistance genes (Alcock et al. 2023). The virulence factors among the microbial communities isolates from oil samples were analyzed using the Virulence Factor Database (VFDB) (Chen et al. 2005) and for comparison with data from VFDB, we used DIAMOND software to determine the virulence factors genes (VFGs).
Isolation of oil-degrading microbes and characterization
To isolate oil-degrading microbes we took 5g of soil samples and added it to 5 ml Bushnell-Haas (BH) medium supplemented with 1% engine oil and incubated in a shaker incubator at 37℃ with 180rpm/min for 7 days.
The turbid bacterial culture (one ml) was transferred to a fresh BH agar medium supplemented with 1% filtered oil. Single colonies were selected, and DNA was extracted from 10 candidate bacterial strains. 16S rRNA sequencing using the primer pairs; 27F and 1492R (Suppl. table 1)was performed at Majorbio, Shanghai, China. The obtained sequences were trimmed, aligned and analyzed using the EzBioCloud16S rRNA tool (Yoon et al. 2017), and NCBI-BLASTn to identify the corresponding microbes.
Quantitative PCR and gene expression analysis.
For the qRT-PCR analysis, we followed the method previously described (Qaria et al. 2018). Briefly, RNA was isolated from P. aeruginosa, A. marplatensis, K. pneumoniae and Leclercia sp. By TRIzol (Invitrogen, USA). Subsequently, 3 µg of RNA was converted to cDNA using SuperScript-III (Invitrogen, USA) and random hexamers according to the manufacturer’s instructions. For qRT-PCR, 40 ng of the first transcribed DNA strand was amplified by using SYBR Fast qPCR Mix (TaKaRa, Japan) with primers targeting iroC, ybtQ, wzt, gmd, clbM genes and 16S rRNA as an internal control. The primer sequences are listed in (Suppl. table 1).
Antibiotic susceptibility testing for microbes isolated from oil polluted soil.
Antimicrobial sensitivity of 4 strains isolated from OPSs and control sample against 9 different antibiotics as published previously (Ranjan et al. 2016). Briefly, was performed on Mueller-Hinton agar (MHA) plates by the M.I.C.E.™ (Oxoid, USA), according to the manufacturer’s protocols. P. aeruginosa, A. marplatensis, K. pneumoniae and Leclercia sp. strains grown on Mueller-Hinton agar medium were collected and washed with PBS.
About 50 µl of 108 of P. aeruginosa, A. marplatensis, K. pneumoniae and Leclercia sp cells suspension was spread on Mueller-Hinton agar medium M.I.C.E.™ corresponding to gentamicin, kanamycin, cefoperazone, polymyxin B, ciprofloxacin, sulfamethoxazole, rifampicin, cefradine and ampicillin were placed on inoculum spread plates and incubated for 16–24 hours. The susceptibility was interpreted by breakpoints defined by the Clinical and Laboratory Standards Institute (CLSI 2022).
Statistical analysis
The statistical analyses were performed using one-way ANOVA followed by Tukey’s multiple-comparison tests wherein ns denotes to non-significant * denotes P < 0.05 ** denotes P < 0.01, *** denotes P ≤ 0.001 and ****denotes P ≤ 0.0001. The data were presented as mean ± the standard error (of mean) from three independent experiments. Graphs were plotted either by OriginPro software (OriginLab, USA) or GraphPad Prism 8.0.2 software (Dotmatics, USA)
{kind=link}