Despite the existence of various anti-phishing techniques, users are still falling victim to these attacks. In the recent decade, ML-based models have been applied widely in URL phishing detection. Some of them designed their model to be applicable for detecting zero-day attacks, while others are not. Table 1 summarizes the recent articles (published in the last five years from 2018 to 2023) studied for this research and depicts which ML methods and data sets are utilized in the purposed frameworks.
Table 1 Summaries of reviewed papers that applied ML models in detecting phishing URLs
|
Reference
|
ML methods
|
Type of data
|
0-day
|
Source of the data set
|
|
Hannousse & Yahiouche, 20213
|
NLP feature extraction + RF*, DT, LR, NB, and SVM
|
Text (URLs)
|
No
|
Created a data set with 11430 samples and 87 features extracted from Alexa and Yandex (for legitimate) and PhishTank and OpenPhish4 (for malicious samples).
|
|
Abdelnabi et al., 2020 - VisualPhishNet
|
CNN and similarity metrics
|
Visual data (screenshot of pages)
|
No
|
Made the largest visual phishing detection data set with 10250 samples
|
|
Wei et al., 2020
|
CNN
|
Text (URLs)
|
Yes
|
10604 phishing URLs from PhishTank5/10604 legitimate URLs from Common Crawl Foundation6
|
|
Ariyadasa et al., 2022- PhishDet
|
Graph CNN + Long-Term Recurrent Convolutional Network
|
Text (URLs and HTML codes)
|
Yes
|
Two different data sets with (40000 and 50000 records were built by collecting legitimate URLs from the Google search engine and phishing samples from PhishTank. A benchmark data set is used for testing (with 46096 samples)
|
|
Bu & Cho, 2021
|
Deep Convolutional AutoEncoder
|
Text (URLs)
|
Yes
|
three real-world URL data sets (ISCX-URL-2016 data set, PhishTank, and PhishStorm) consisting of 222,541 legitimate and phishing URLs
|
|
Belfedhal & Belfedhal, 2022
|
MLP + TF-IDF
|
Text (URLs)
|
No
|
A benchmark data set of 73575 phishing and legitimate URLs
|
|
Naresh Kumar D & Panimalar, 2020
|
RF, KNN, DT, SVM, LR
|
Text and structured data (URL, source code, session, type of security, protocol, and website type)
|
No
|
Not described in the article
|
|
Sahingoz et al., 2019
|
NLP feature extraction + DT, Adaboost, K-star, KNN (n = 3), RF, SMO, NB
|
Text (URLs)
|
Yes
|
Ebbu2017 Phishing Data set: a data set with 73,575 URLs (36,400 legitimate URLs and 37,175 phishing URLs)
|
|
Ghalati et al., 2020
|
Semantic feature extraction + RF, LR, NB
|
Text (Protocol, Domain, Path, URL, IP)
|
Yes
|
Ebbu2017 Phishing Data set 74k URLs, 36k are legitimate and 37k are phishing. DMOZ data set and the Alexa.com data set for providing benign data sources
|
|
Chatterjee & Namin, 2019
|
Deep Reinforcement
|
Text (URLs)
|
Yes
|
Ebbu2017 Phishing Data set
|
*RF: Random Forest, DT: Decision Tree, LR: Logistic Regression, SVM: Support Vector Model, NB: Naïve Bayes, KNN: K-Nearest Neighbors
[3] This data set is applied in our research
[5] https://phishtank.org/
[6] http://commoncrawl.org/
As can be seen, all the studies utilized supervised classification models. Also, six out of ten papers have used Neural Networks (NN) and Deep Learning in their models and only two of them applied non-NN classification models. In addition, except for one research (Abdelnabi et al., 2020) that used visual data in their model, other papers utilized URLs in their work, and some of them applied NLP-based feature extraction methods to build a structured data set (Ghalati et al., 2020, Sahingoz et al., 2019, Belfedhal & Belfedhal, 2022). The table also shows that six out of ten works are examined in detecting zero-day attacks. Here are more details of how each of these studies designed and applied ML models in URL phishing detection.
(Abdelnabi et al., 2020) introduced VisualPhishNet, a similarity-based phishing detection framework, which applies Convolutional Neural Network (CNN). Using a similarity metric, this framework detects phishing websites, particularly on pages with new appearances. The authors also built the largest visual phishing detection data set by crawling active phishing pages on the PhishTank website and collecting screenshots from the pages which resulted in 10250 samples. The evaluation metrics they considered in detecting phishing samples were elements’ sizes, colors, locations, and website languages. Convolutional Neural Network is also applied in other research to recognize phishing webpages by only analyzing URLs (Wei et al., 2020). The authors explained that, unlike other studies that separate URLs into different parts and analyze each part to identify phishing attacks, their model only needs to encrypt URLs as one-hot character-level vectors. Then the vector is fed to CNN and the model can detect phishing samples with an accuracy of almost 100% and is effective for detecting zero-day attacks as well.
PhishDet is another neural network-based framework that is applied to recognize zero-day phishing attacks. Being developed based on Graph Convolutional Neural Networks and Long-Term Recurrent Convolutional Networks, this model can detect malicious websites by analyzing their URLs and HTML codes with an accuracy of 96. 42%. To maintain its high performance, PhishDet requires frequent retraining over time (Ariyadasa et al., 2022). Utilizing a Deep Convolutional AutoEncoder (CAE), (Bu & Cho, 2021) provided a character-level URL feature modeling to detect zero-day phishing attacks. They applied three real-world phishing data sets with 222,541 URLs to examine their model and considered the Receiver-operating characteristic (ROC) as the metric for comparing their results with the results of other models in the literature.
(Belfedhal & Belfedhal, 2022) presents a lightweight system for real-time detection of phishing webpages using a neural network method and features extracted from URLs. The system uses a multilayer perceptron (MLP) model and two categories of features: lexical features extracted from the URL strings and tokens frequency using the TF-IDF algorithm. Experimental results showed that the system achieved a false negative rate of only 1.35%.
Among the reviewed articles, one considered the non-static nature of phishing websites and used reinforcement learning to overcome this issue. (Chatterjee & Namin, 2019) presents a new approach for detecting malicious URLs through a Deep Reinforcement learning-based model that adapts to the evolving nature of phishing websites. The model is developed using a deep neural network and is capable of learning features associated with phishing website detection. The performance of the model is evaluated using precision, recall, accuracy, and F-measure, and the results are compared with existing phishing URL classifiers.
Regarding non-NN models, four articles have been done to examine classification techniques. (Naresh Kumar D & Panimalar, 2020) proposes an ML-based classification algorithm that uses heuristic features such as URL, source code, session, type of security, protocol, and website type to detect phishing websites. The algorithm is evaluated using five machine learning models, and the random forest algorithm is found to be the most effective, achieving an attack detection accuracy of 91.4%.
Also, (Sahingoz et al., 2019) propose a real-time anti-phishing system that uses seven different classification algorithms and natural language processing (NLP)-based features. The system is distinguished from other studies in literature by its language independence, use of a large data set, real-time execution, detection of new websites, and use of feature-rich classifiers. The experimental results showed that the Random Forest algorithm with only NLP-based features achieved the best performance for detecting phishing URLs.
Another research used semantic features from domains and URLs to detect malicious URLs (Ghalati et al., 2020). The authors introduced an adaptive method that can dynamically change based on new feedback received on 0-day attacks, and they found that Random Forest has the highest accuracy of over 96% with more interpretability and performance benefits.
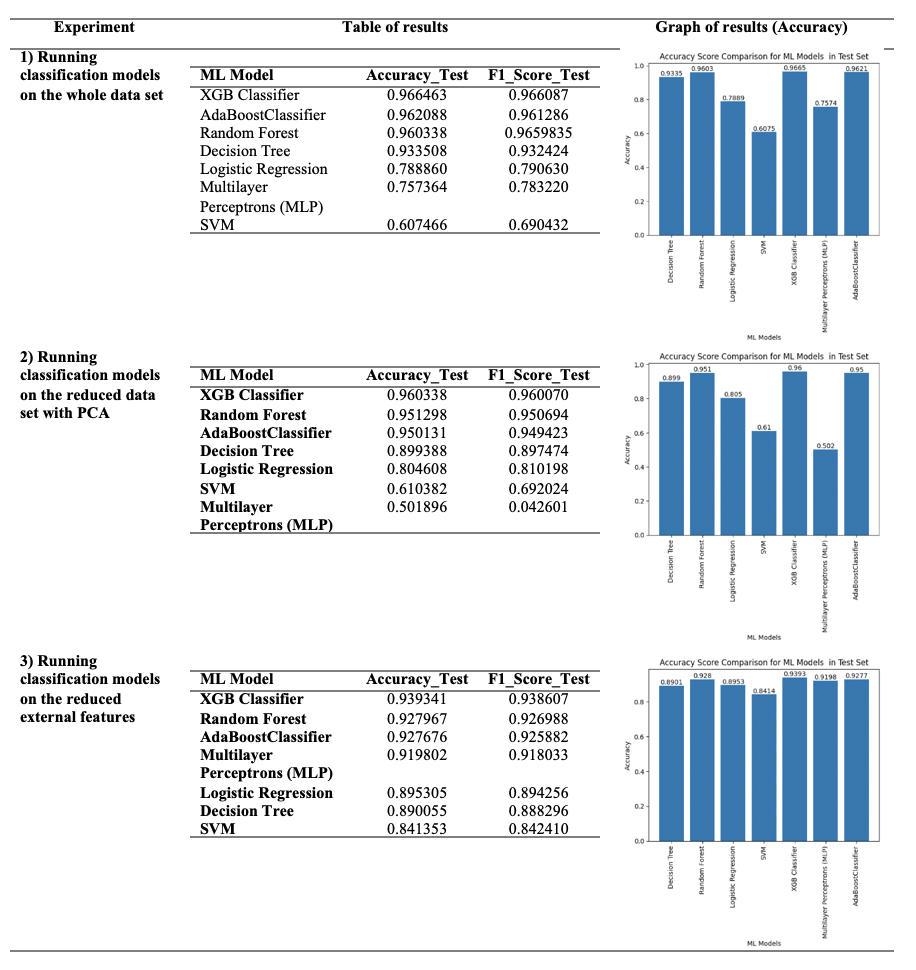
One of the studies that applied non-NN models is performed with the main objective of creating a benchmark balanced data set that includes an equal number of benign and malicious URLs (Hannousse & Yahiouche, 20). The collected URLs are processed, and 87 features are extracted from URLs, web page contents, and external resources that are obtained by querying third-party service providers (such as Alexa and WHOIS). The authors then applied five different classification methods (RF, DT, LR, NB, and SVM) to see their performance on the created data set. However, they did not consider the issue of zero-day attacks in their work. This data set is utilized in our research to examine the performance of multiple classifiers (RF, DT, SVM, LR, MLP, XGBoost, and AdaBoost) with the whole data and by applying dimension reduction techniques and their performance on the zero-day test set. We also aimed to examine whether tuning hyperparameters of the given models leads to a higher performance score. In addition, we tried to answer the question of the impact of the external features on the models’ performance. Our proposed model is described in detail in the next section.
{kind=link}