Background There is a huge body of scientific literature describing the relation between tumor types and anti-cancer drugs. The vast amount of scientific literature makes it impossible for researchers and physicians to extract all relevant information manually.
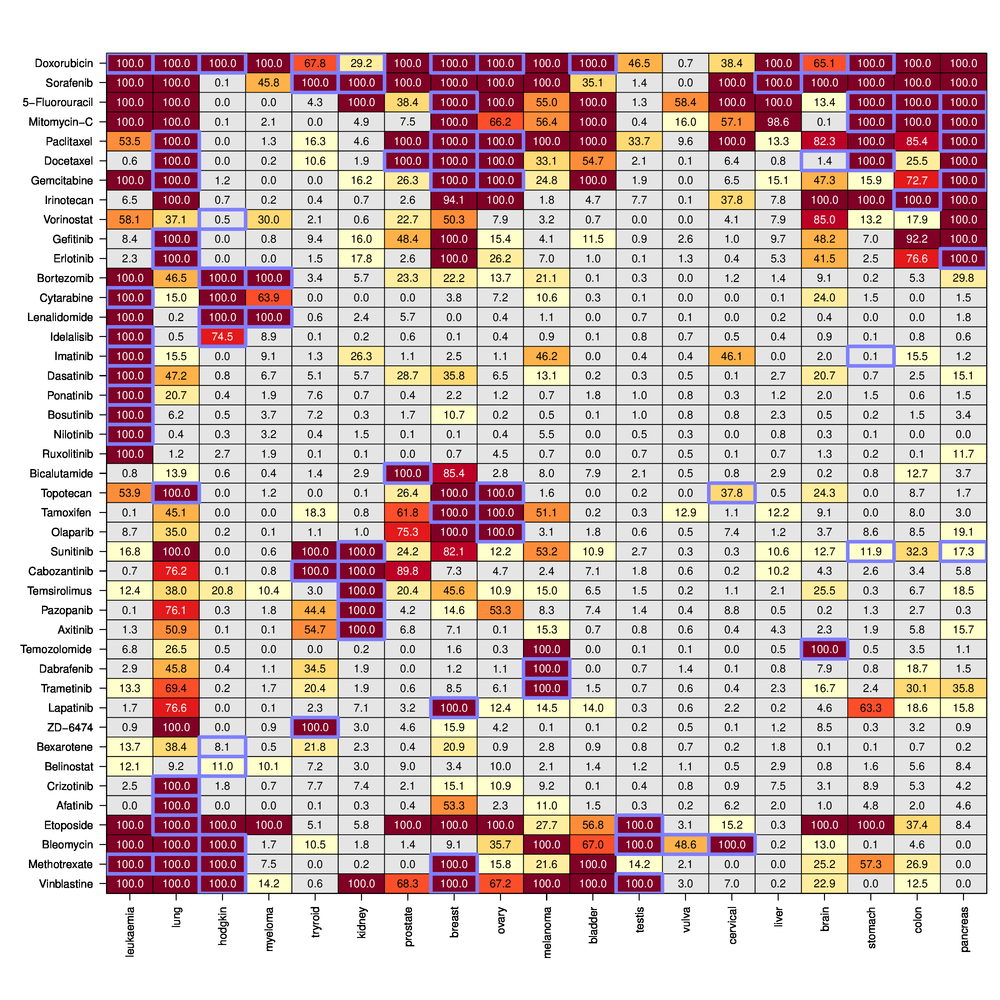
Methods In order to cope with the large amount of literature we apply an automated text mining approach to assess the relations between 30 most frequent cancer types and 270 anti-cancer drugs. We apply two different approaches, a classical text mining based on named entity recognition and an AI-based approach employing word embeddings. The consistency of literature mining results is validated with 3 independent methods: first, using data from FDA approval, second, using experimentally measured IC-50 cell line data and third, using clinical patient survival data.
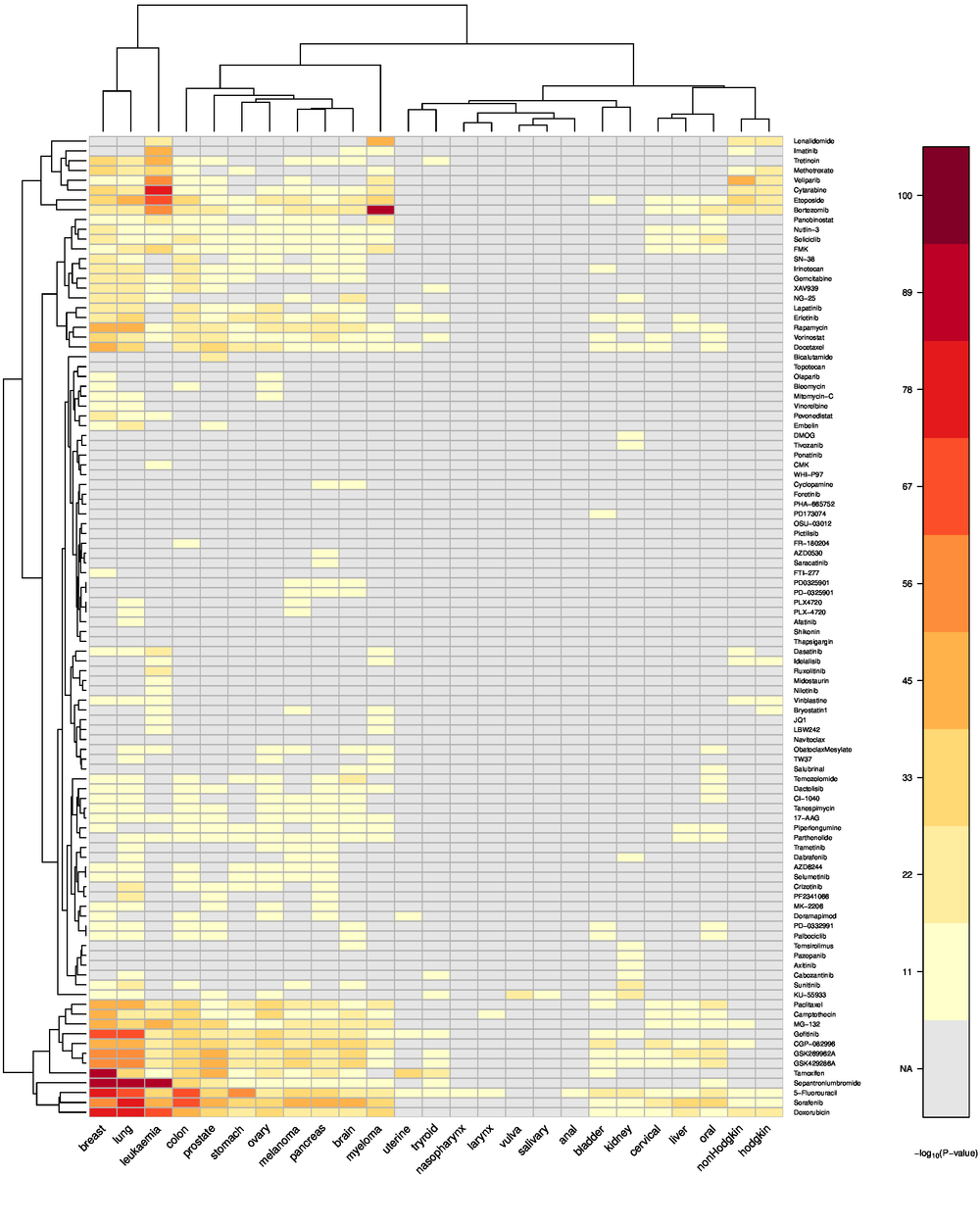
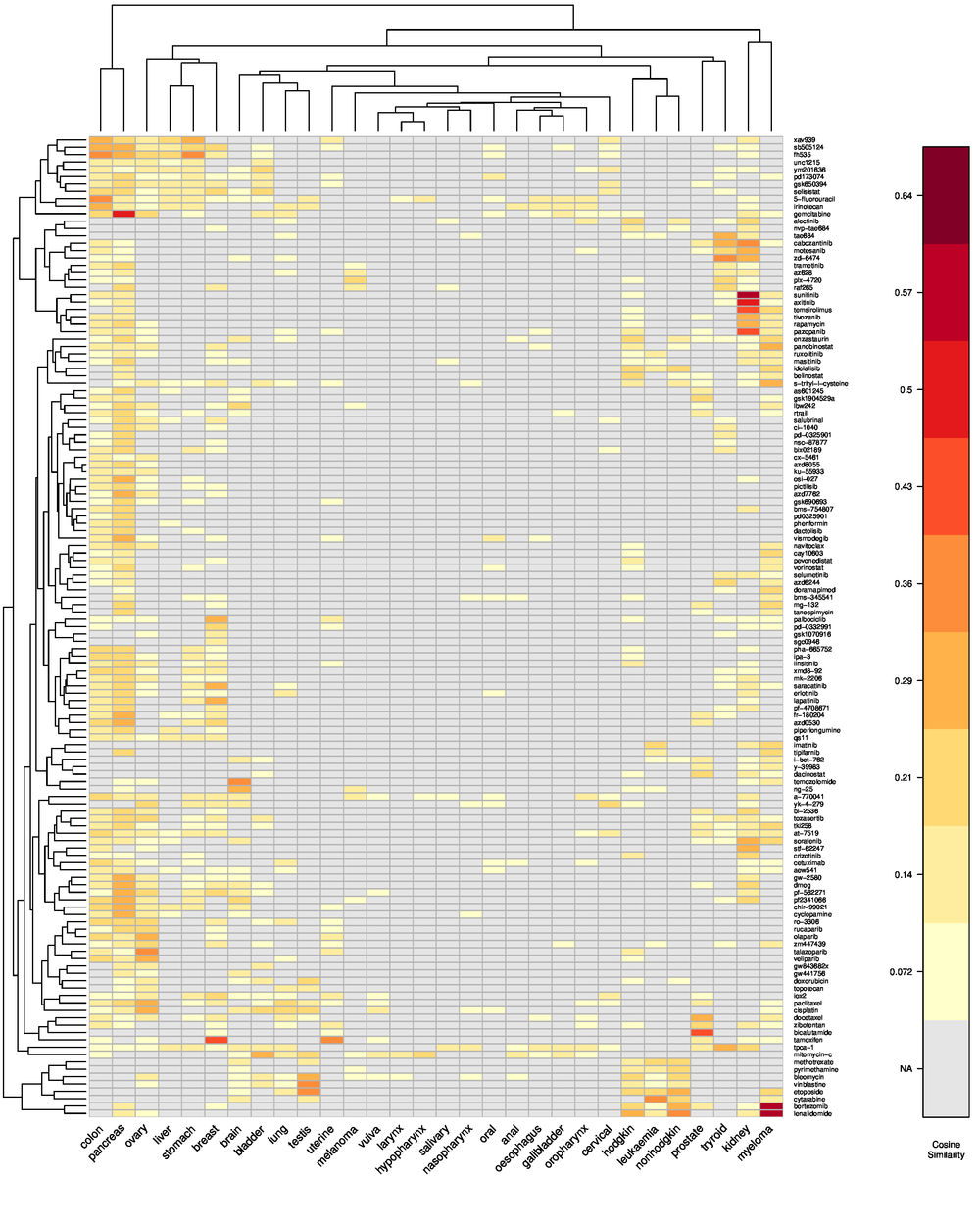
Results We demonstrate that the automated text mining is able to successfully assess the relation between cancer types and anti-cancer drugs. All validation methods show a good correspondence between the results from literature mining and independent confirmatory approaches. The relation between most frequent cancer types and drugs employed for their treatment are visualization in a large heatmap. All results are made accessible in an interactive web-based knowledge base using the following link: https://knowledgebase.microdiscovery.de/heatmap
Conclusions Our approach is well suited to assess the relations between compounds and cancer types in an automated manner. Both, cancer types and compounds can be grouped into different clusters. Researchers can use the interactive knowledge base to inspect the presented results and follow their own research questions.
{kind=link}
{kind=link}
{kind=link}