Electronic health records refer to the digital version of patient’s paper chart and the associated health information systems, which have been widely applied in hospitals to record the disease variety, therapeutic regimen, test results and radiological images [34]. Prediction of ADRs/ADEs basing on EHR can help improve the quality of health care, however, the challenge of identifying ADEs from these observational data deserve attention. Due to the combination of structured and unstructured data, traditional statistical methods were difficult to predict adverse events basing on EHR. Certain keyword changes, such as altering the sequence of instructions or expressions, might have a great impact on the prediction results. ML algorithms have gained widespread applications in medical fields, including prognosis prediction, which aresuitable for complex data environments. Several Advanced ML algorithms, such as XGBoost, Light Gradient Boosting Machine (LightGBM), CatBoost, Gradient Boosting Decision Tree (GBDT), and RF, have been developed, offering refined techniques. There have been several systematic review articles on patient safety events signal detection using ML. However, these systematic reviews usually focused on the identifying and diagnosing safety events, the studies focused on the prediction of ADRs/ADEs were still lacking. In this study, we conducted systematic review and meta-analysis for the use of ML techniques and algorithms in predicting drug-related harm from EHRs and clinical notes.
The results showed that the most investigated database was the Stockholm EPR corpus in 10 including studies [27,29,31–33]. This database, which comes from Karolinska University Hospital in Stockholm, Sweden, contains large amounts of diagnosis information, drug administrations, clinical measurements and clinical notes in free [32]. MIMIC-IV was also used to establish the prediction models, which was the result of a collaboration between Beth Israel Deaconess Medical Center and Massachusetts Institute of Technology. The data of MIMIC-IV can be deidentified, transformed, and made available to researchers who have completed training in human research and signed a data use agreement [35]. Its available information includes patient measurements, diagnoses, procedures, treatments, and deidentified free clinical notes [31]. One study used a Chinese database [30]. This database included demographic data, procedures, and clinical notes (including personal history, diagnoses, and medications), while it did not mention more details about the database, including reference and the information of hospital, patient and data period 30. In the Chinese database, Stockholm EPR corpus and MIMIC-IV, patient data were described by both unstructured clinical narratives and by structured data regarding [27, 30, 36]. Three studies were based on self-built database, which were conducted in older adults, children, and all population [5, 26, 28], which data were structured clinical data, extracted from EHR of hospital by researchers. International Classification of Disease, Version 10 code was applied as standard terminologies for diagnoses in the studies which based on Stockholm EPR corpus and MIMIC-IV [16,27,29,31–33].
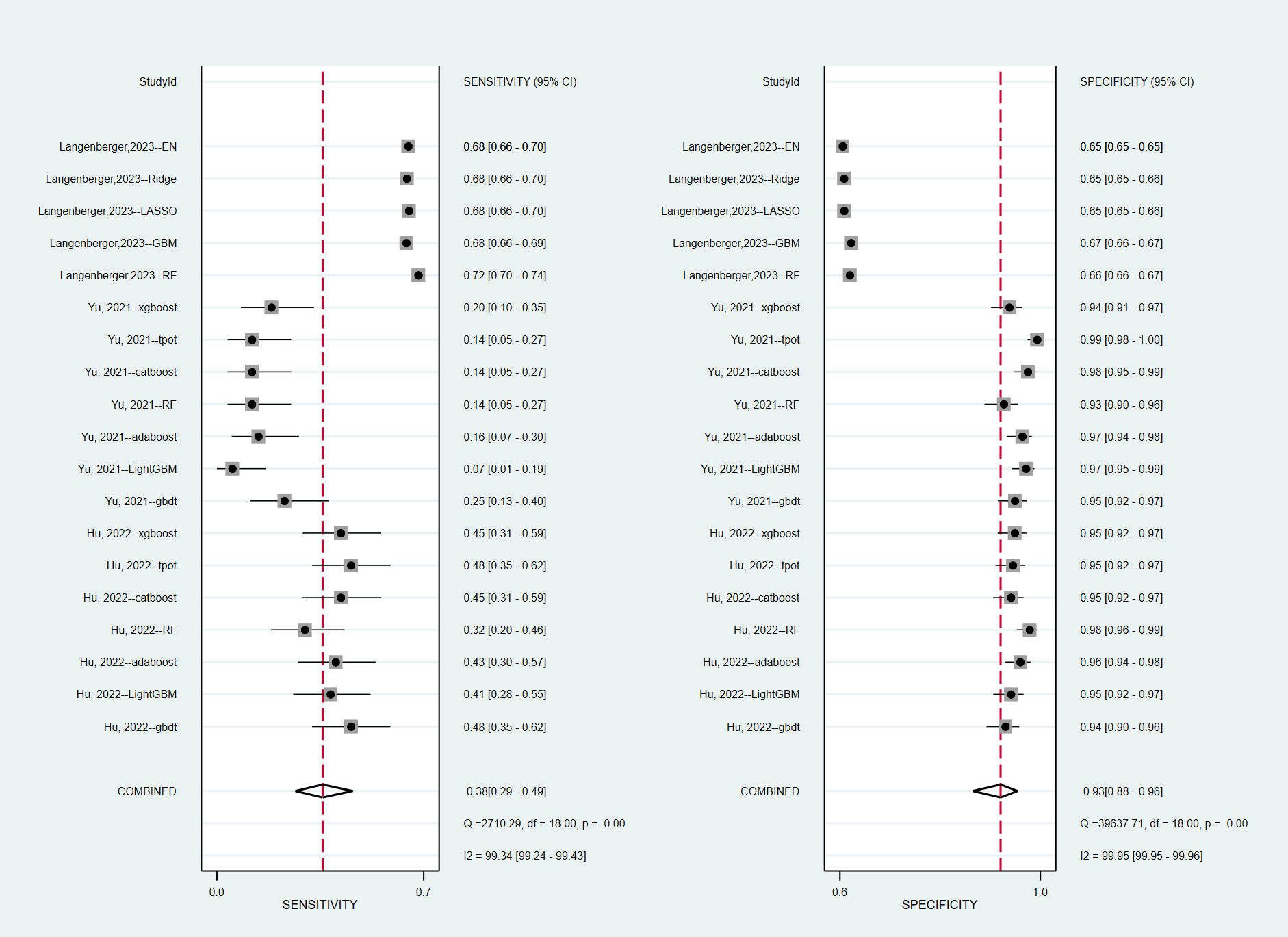
There were 20 type of ML algorithms applied to establish the prediction ADR/ADE models. In these ML algorithms, ensemble learning was the most commonly used categorization of models. It can combine predictions from multiple single weak learners to obtain more reliable and generalizable predictions [37]. Compared to a single weak learner, the linear combination of weak learners or majority voting in classification problems in regression problems can obtained the superior prediction [38]. Ensemble learning methods include bagging and boosting algorithms. Boosting algorithm trained weak learners, computed predictions, and selected the misclassified training samples. And then, it trained the subsequent weak learner with an updated training set that includes the misclassified instances from the previous training set [39]. Boosting algorithms, including GBDT, XGBoost, LightGBM, and so on, were applied in various sectors. The review revealed that five studies reported the performances of boosting algorithms [5, 16, 26, 30, 31], the aggregate performances of them were good. The average AUC and precision of boosting algorithms were 85.20% (72.00–92.00) and 46.78% (10.10-68.57). Among boosting algorithms, AdaBoost and XGBoost might perform better than LightGBM, gradient boosting machine (GBM), and GBDT basing on AUC, F1 scores and precision, while meta-regression could not be calculated due to lack of contingency tables.
Bagging algorithm, was aggregating the predictions of multiple decision trees, was different from boosting algorithm. It resampled data from the training set with the same cardinality as the starting set [40]. Therefore, bagging algorithm can reduce the classifier’s variance and overfitting. The representative algorithm was RF which was also the most frequently reported algorithm with a total of nine studies reporting [5,16,26,28,29–32]. RF can improve the predictions of the decision tree’s base classifier by using bagging approach [41]. It was widely accepted that EHR data with large numbers of sparse features could lead to the low predictive performance of RF [27]. Therefore, the RF algorithms in the included studies were improved by adjusting the configuration, learned weights, tree sizes, or combining with different resampling approach in some including studies. The results showed that the average AUC and precision of non-improved RF were 80.87% (74.30–94.00) and 35.89% (9.60–75.00), which of improved RF were 83.48% (74.64–94.57) and 51.13% (48.49–52.70). Among these modified RF, combined with resampled until an informative feature found or until no more features might have the best performance, the AUC and F1 score were 94.57% and 88.89%, respectively [27]. However, meta-regression could not be also calculated for the same reason.
Support vector machine, as one of the most popular ML algorithms, had been extensively applied into face recognition, disease prediction, image retrieval, data mining and other fields, and so on. Its basic idea was to find the maximum margin-type hyperplane in the input space which separated the training dataset [42]. It can solve the pattern recognition problems of small samples, nonlinearity and high dimension, especially in dealing with classification problems [43]. However, the performance of SVM was not as well as ensemble learning, which average AUC were just 63.00% (59.00–67.00). The reason might be the number of enrolled patients in the including studies were high, which resulted in poor performance of SVM [29–31].
Some studies reported the results of LR which was the common traditional statistical methods. The performance of LR was not inferior to non-LR methods, such SVM, artificial neural network (ANN), K-Nearest Neighbor (KNN) or Naïve Bayes (NB) in some studies [16, 30, 31]. The meta-regression showed that the non LR methods had a higher specificity than LR method, but less sensitively. Therefore, researchers should not blind faith in some novel ML algorithms, LR might also perform well. We should select the appropriate algorithms based on the unique research issue and application scenario.
Eight studies reported the type of ADRs/ADEs [5,16,26,27,29,31–33]. The incidence rates of different adverse reactions have large variation due to the difference in population and database. In these studies, allergy was most commonly mentioned, which incidence was between 1% and 6%. Drug allergy could be associated with any kind of medication, which could be classified to IgE-mediated, cytotoxic, immune complex, and cellular mediated [44]. Most allergies were transient, while some of them could lead to serious consequences, such as drug reaction with eosinophilia and systemic symptoms and Steven-Johnson syndrome. Over sedation\hypotension were also common and associated with blood pressure medications, sedative hypnotics or anesthetics. The incidence rate was in 0.3–2%, which might be higher in pediatric inpatients [26]. The reasons might be that the dosage of sedative hypnotics or anesthetics had great individual variations among children, and children’s sensitivity to these drugs also varies greatly [45]. In addition, respiratory depression, bronchospasm, and dyspnea were only fund in children. They might also be related to the use of sedative hypnotics or anesthetics; hence, these drugs should be used with caution in children.
Four studies reported the risk factors of ADR/ADE [5, 16, 26, 30]. Although the risk factors were variable in different studies or database, the length of stay, number of drugs, age, and high-risk drug used, were the commonly mentioned [5, 16, 26, 30]. The cross-sectional studies had shown patients who experienced drug-related injure received more medications during their hospitalization and had longer stays [2, 46, 47]. Age was also an important risk factors of ADR/ADE. Older patients were more likely to experience drug-related events due to multiple co-morbid illnesses, polypharmacy, difficulty monitoring prescribed medications, and age-related changes in pharmacokinetics and pharmacodynamics [48]. However, the younger older people were likely to experience ADEs than the older due to receiving high-risk medications [5, 14]. The frequently mentioned high risk drugs included glucocorticoid, anticoagulants, non-steroidal anti-inflammatory drugs, and chemotherapeutic drug, all of which had been shown to be high risk for ADEs [49]. For this reason, surgery was a protective factor of ADR/ADE. This was due to the fact that surgical patients were commonly only with intravenous fluid therapy during surgery, and were rarely treated with high-risk drugs, and therefore had a lower risk of ADEs. These results indicated that reduced lengths of hospital stay, simplified treatment regimens, and avoided the use of high-risk drugs could avoid ADR/ADE. Although these risk factors were often difficult to avoid in clinical treatment, physician, nurse or pharmacist should pay close attention to patients with risk factors and promptly treat ADR/ADE when it occurred.
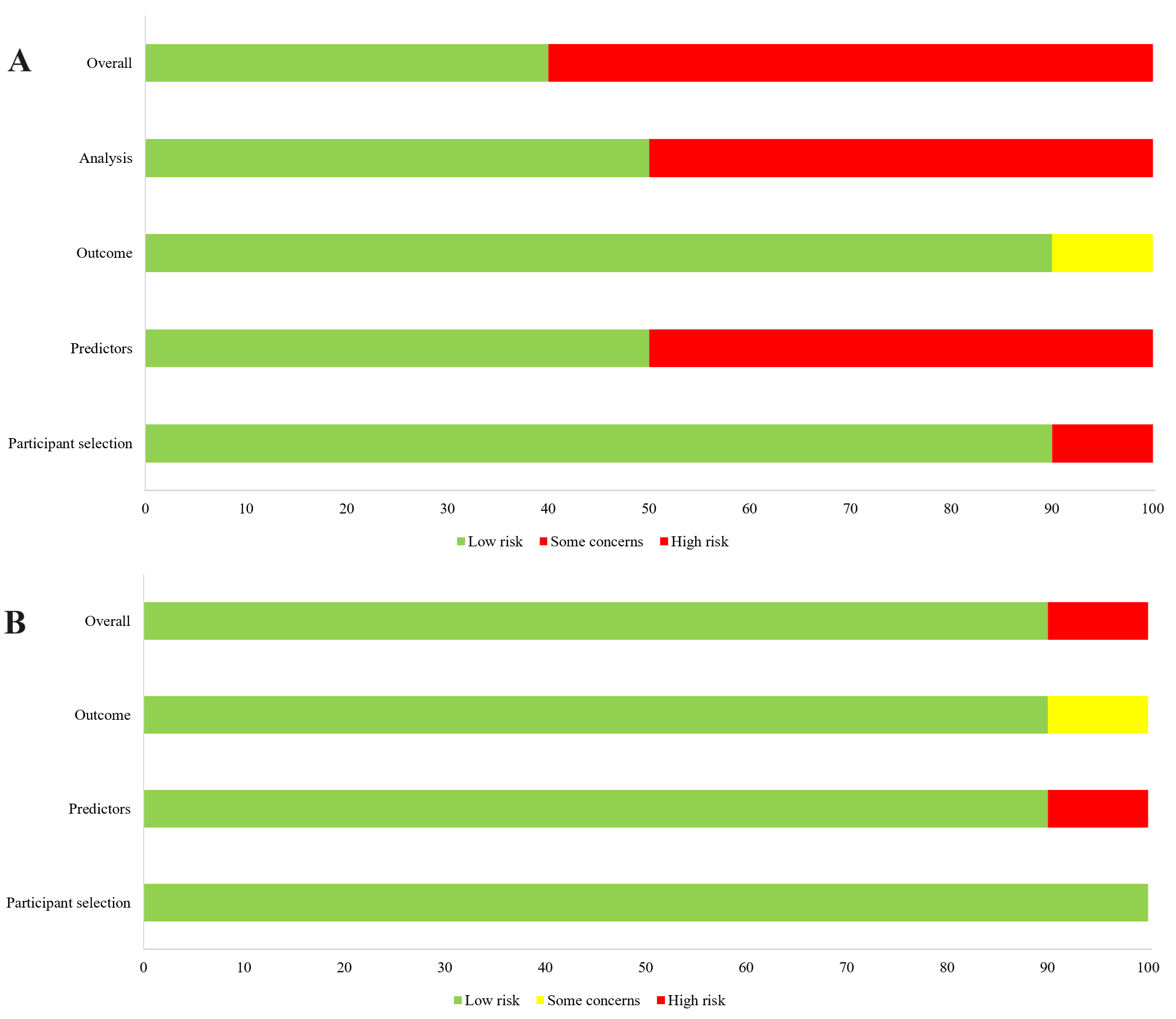
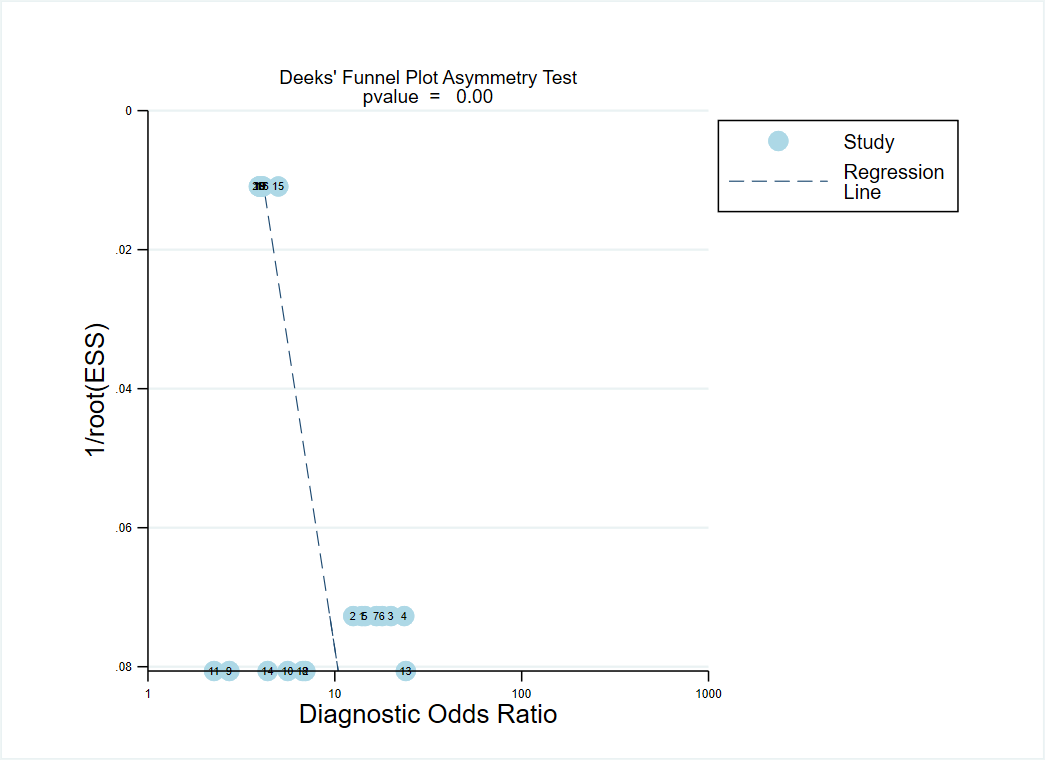
There are several limitations in the present study. First, the quality of enrolled studies was not high. The results of quality assessment based on PROBAST and ChAMAI checklist showed that only three studies had the low risk of bias and scored higher than 25 (full marks was 50) [5, 16, 26]. Reporting data processing procedure is the important part of the model development, which can improve reproducibility, transparency, thorough explanations, however, these dimensions have a low score among studies. Most of the included studies did not report data description and data preprocessing tasks procedure. In addition, the studies basing on self-built database or the Chinese database did not apply standard terminologies, though using standard terminologies/ontologies might model performance and generalization [5, 26, 30]. Therefore, the high-quality researches were need to explore the optimal prediction model and risk factors of ADR/ADE. Second, contingency tables, which could be used to simply compare predictive performance by pooled estimate, were available in only three studies, involving 13 models. Third, great heterogeneity was observed in the including studies due to the differences in the database based, predictors, ML algorithms, hyperparameters and population included. For the research exploring predictive model, heterogeneity might only be avoided under some harsh conditions, such as the similar disease, age or region of patients, and the similar ML models and parameter, hence, the low heterogeneity could be difficult to obtain. Fourth, ML methods can improve prediction performance, but certain input variables such as chief complaint can be better processed when highly advanced pre-processing methods, such as natural language processing, are applied. Unfortunately, no studies have combined this method with ML for ADR/ADE prediction. Finally, application of new ML and deep learning methods for prediction of drug safety events on EHR have been rare, such as convolutional neural network, recurrent neural network, bidirectional long short-term memory with conditional random field algorithms, and so on. Therefore, researcher should pay more attention to the innovative ML algorithms for improving the ability of model prediction and promoting the application of achievements in the future.
{kind=link}
{kind=link}
{kind=link}
{kind=link}