To our knowledge, we have conducted the first study looking at GPT-4’s performance in the MLA testing format focusing on specific competencies, question types and the provision of an MCQ prompt. Overall, GPT-4 performed at a passing standard for a final-year student undertaking the MLA. The presence of multiple-choice options removed uncertainty and strengthened the accuracy of the tool, whereas there was a global decline in performance when answering open-ended questions. GPT-4 only demonstrated significant differences in accuracy when answering open-ended questions targeted at different points within the patient journey.
Kung et al.’s study showed that ChatGPT could pass the USMLE, and since then, both the strength of AI and the format of UK medical school final exams have significantly changed 13. Studies by Lai et al. and Al-Shakarchi et al. have been conducted on ChatGPT’s efficacy in passing the new UKMLA. Lai et al.’s study demonstrated that ChatGPT is capable of passing the UKMLA but concludes it is most suited as a supplementary, monitoring or learning tool rather than inpatient diagnosis or interaction 15,16. Al-Shakarchi et al.’s study analyses questions using a specialty-based approach suggesting that ChatGPT can perform well applying simple deductive reasoning to its vast data set 16. However, ChatGPT was found to overlook fine details in medical knowledge-based decisions and lacked patient interaction skills and the ability to diagnose and holistically manage cases with accurate prescribing skills 17. Overall, ChatGPT appears limited as an independent tool and requires significant supervision to ensure optimal patient-specific decisions and interactions.
With more powerful AI, it follows that AI should answer medical scenarios with improved accuracy and thus pass the MLA, the UK’s parallel to the USMLE. Indeed, GPT-4’s score of 86.3% and 89.6% in papers one and two respectively places the AI beyond the average performance of a medical student. Furthermore, we found no significant differences in the performance of GPT-4 across question types or topics. Strength in breadth of knowledge supports an LLM’s incorporation into clinical practice as an aid to increase junior doctors’ diagnostic sensitivity.
Maitland et al. tested LLM’s ability to pass the Membership of the Royal College of Physicians (MRCP) part 1 and 2 examination questions, increasing the required depth of knowledge from the LLM and nevertheless showed that it far exceeded the required pass mark 18. However, analysis of ChatGPT’s mistakes suggests that the LLM focused on general cues in the vignette while potentially neglecting important nuances. LLM’s breadth over depth of knowledge cautions against use in applications and technologies with patient-specific medical impact. Importantly, Maitland et al. recommend that errors should be fully understood before ChatGPT is utilized to supplement clinical practice 18.
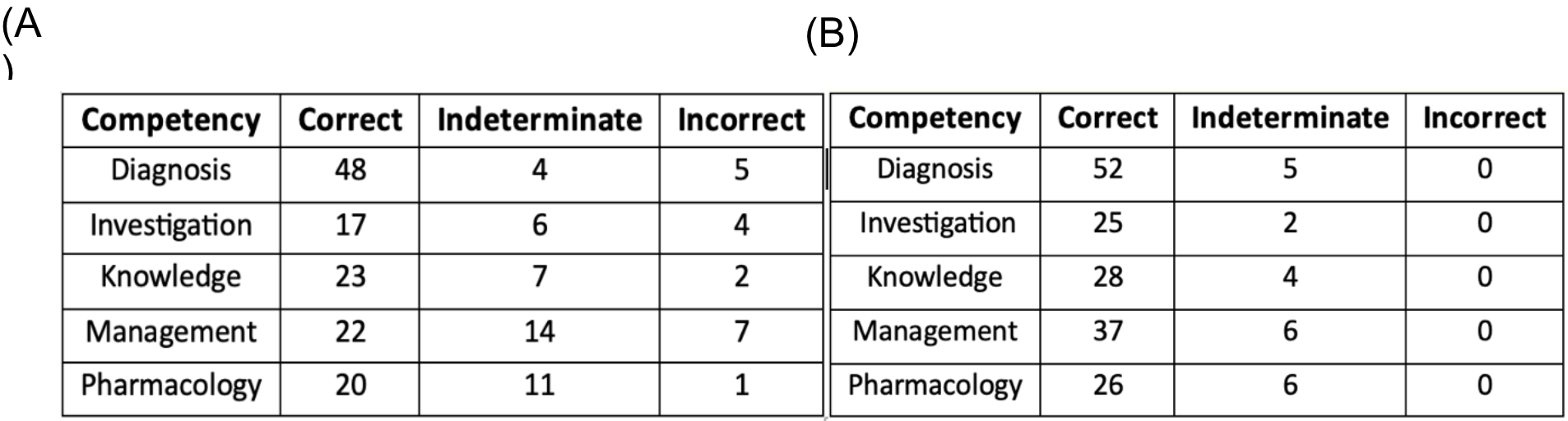
In the clinical environment, there are no set options for the AI to choose from. When multiple-choice options were removed and GPT-4 was prompted to independently determine the best answer, GPT − 4 showed a clear reduction in accuracy across papers one (-24.8%) and two (-14.9%). Despite question stems asking for a single best answer, we found that GPT-4 began to provide a greater proportion of ‘indeterminate’ responses, especially when tackling patient pharmacology scenarios. However, inconclusive answers may prove detrimental in an exam format, but many patient and service provider factors alter the approach to managing patients, and a definitive answer may prematurely focus the treatment and prove detrimental to the patient’s care. Acknowledging uncertainty or variation in the evidence and presenting multiple options may serve junior doctors better by giving general guidance before allowing clinician-led final decisions.
Distractors in clinical scenarios may highlight further gaps in GPT-4’s suitability for clinical practice. Counterintuitively, eight open-ended questions were answered correctly by the AI and were ‘indeterminate’ with multiple-choice options provided. Plausible alternatives and red herrings may impact GPT-4’s evaluation of answers and practitioners must be cautious of the reasonable and thus convincing errors in diagnosis and treatment AI can suggest. Nuances in vocabulary and patterns in the exam questions’ phrasing are familiar to junior doctors, but AI may require more training before reaching equivalence. By extension, the many distractors in practice will require thorough filtering, a process inherent to taking a good clinical history. Furthermore, GPT-4’s output may produce convincing but entirely false suggestions in the well-described ‘hallucination’ phenomenon 9,19,20. LLMs may create a linguistically coherent paragraph on any question prompt by combining information from multitudes of sources and thus derive a sequence of words by using probabilities rather than analysis of the question prompt 21. In questions with multiple options, GPT was able to match question stems to training data and select the response closest to information in its data set but when the same questions were asked in open-ended form, ChatGPT could not match terminology or produce significantly right answers resulting in wrong or inconclusive answers.
Importantly, GPT’s equivalence, or even superiority, to junior doctors when answering MCQ questions does not supersede all competencies required for a student to graduate into clinical practice. Objective or Integrated Structured Clinical Examinations (OSCEs or ISCEs, respectively) evaluate a student’s communication, patient examination, and data interpretation abilities, culminating in a test of clinical reasoning by deriving diagnoses and management plans. While ChatGPT and other LLMs might excel in input-based cues by harnessing training datasets, their inability to detect and integrate social, verbal, and visual cues restricts LLMs from being supplementary tools rather than operating with minimal physician input.
GPT remains limited by the standard of its training. Despite impressive results, analysis of GPT’s performance across stages of the clinical process showed a significant decrease in performance in the ‘management’ questions from the ‘diagnosis’ scenarios. The management of conditions improves as new research challenges current practice, but patient presentations remain comparatively constant across many pathologies. Thus, GPT’s relative ease in making diagnoses reflects that of medical practitioners and keeping up to date to ensure optimal patient treatment requires LLMs to be trained on relevant data. As guidelines continue to vary by hospital trust within the National Health Service (NHS), LLMs will require continuous and rigorous regional training to ensure consistency in patient care before application in practice. Storage and computational power may prove restrictive to applying AI in a rapidly evolving field such as medicine.
Ethical dilemmas may also hinder the application of AI in clinical medicine. Medical research often underrepresents minority populations, and thus its results cannot be generalised to train AI-based models 10. Diagnostic errors made by LLMs due to insufficient or flawed training could detrimentally influence clinical decisions. Furthermore, LLM black box algorithms obscure its decision-making process so clinicians cannot appraise the model’s process and output 22. Additionally, care must be taken to prevent the depersonalisation of care that patients may experience and the deskilling of healthcare professionals due to an overreliance on AI. No margin of error can be made when making patient care decisions; practitioners must apply caution when incorporating LLM outputs within medical practice.
Flaws in GPT-4’s performance likely result from outdated, globally acquired, unverified training data, not specific to medicine 1. Simultaneously, the diversity of the training data makes GPT’s ability to answer a range of topics and question structures in the MLA remarkable. Pairing GPT-4’s knowledge with improvements enabling GPT-4 to interpret clinical images, such as cardiac monitoring and X-rays, will further broaden its clinical application and potential as a screening tool. Additionally, in an era of big data, unique variables such as patient’s genetic profiles will soon influence clinical decisions. AI’s ability to integrate expanding quantities of data may identify optimal treatment strategies for patients, help structure complex summaries or flag abnormalities buried in years of patient documents and results. Herein lies an exciting potential to harness the power of LLMs within medicine, but analysis of LLMs’ ability to extract all salient details from patient histories is required to ensure safe and reliable outputs.
A rapidly evolving application of ChatGPT can be found in the medical education field. Khan et al. highlight ChatGPT’s utility in assisted teaching, automating scoring systems, personalised learning, research summarization, and generating clinical scenarios 23. Many medical education platforms, question banks and OSCE practice tools are focussing on the integration of AI into producing questions and simulated patients, a typically labour-intensive process. As the role of AI becomes clearly defined within medical education, new generations of clinicians will use AI-enhanced tools to train for practice 24.
Limitations exist within this study’s design. We studied GPT-4s applicability to clinical practice using an exam with carefully designed and topic-specific questions. Naturally, exam questions cannot reflect reality, where relevant clinical information must be paired with a breadth of investigations to decide the diagnosis or management plan. Furthermore, GPT-4 is not trained on the UK-specific guidelines which dictate the MLA’s correct answers. Thus, a model trained using information consistent with the assessment may improve its score, and a sample size greater than 200 will better highlight the key deficiencies of LLMs applied to medical scenarios. Additionally, inputting open-ended questions first followed by MCQ-included questions could introduce ChatGPT’s answering bias. ChatGPT is an LLM that is meant to learn from in-context dialogued human feedback and hence, we cannot ascertain the extent to which the initial question input influenced the answers it selected when inputting questions with MCQs 25.
{kind=link}
{kind=link}