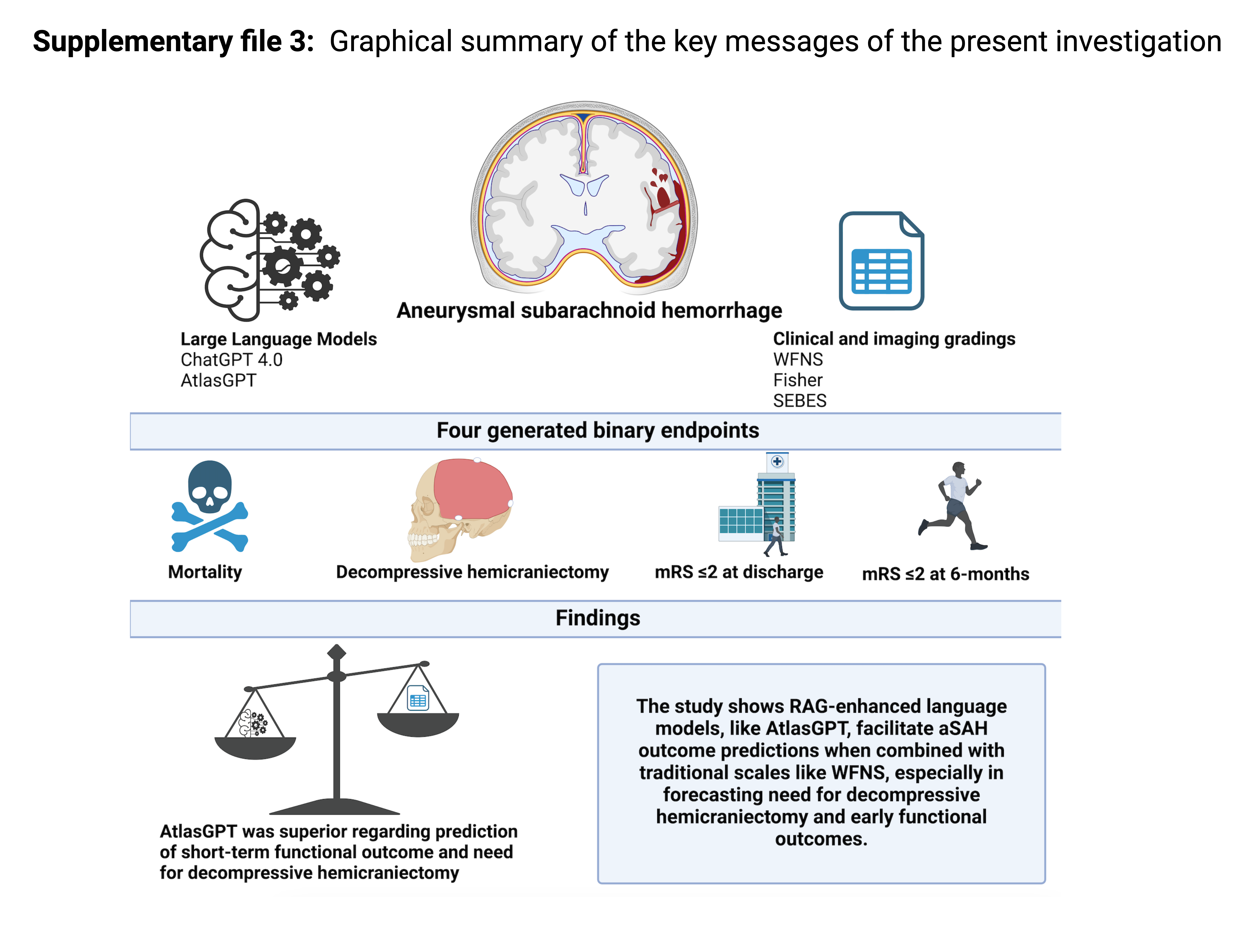
The present study compared the prognostic value of the retrieval-augmented generation techniques enhanced large language model AtlasGPT based on peer-reviewed reliable neurosurgery-specific evidence, the large language model ChatGPT-4.0 with well-validated clinical and imaging scales. The prognostic performance of AtlasGPT to predict the functional outcome at discharge and the need for decompressive hemicraniectomy in aSAH based on characteristics at hospital admission demonstrated substantial roles for artificial intelligence in clinical practice (see supplementary file 3). Nevertheless, these results necessitate extensive discussion.
Both language models showed responses variabilities with slightly more variabilities in the AtlasGPT language model. However, we ran three iterations of four binary questions for 82 patients in two language models and observed only 21 instances of response variability (21/656; 3.2%). To address this issue seriously and reduce potential bias caused response variability, we ultimately took the mean value of the responses for statistical processing. Nevertheless, it has to be noted that our investigation is focused on the most advanced ChatGPT version currently available, which requires a paid subscription (namely, the GPT-4-based model). The freely accessible and more commonly used version is based on the 3.5 model, which might produce less reliable predictions with more response variability and more temporal instability 16. This demonstrates that artificial intelligence can be most effective when integrated with “human intelligence”, such as the expertise of a supervision by a clinician. Additionally, it highlights the necessity for users to closely monitor the application of large language models in clinical settings. Decisions to treatment limitations and prognosis are inherently challenging, demanding human attributes such as long-term professional expertise, empathy, and emotional insight. In contrast, large language models are purely machines operating on stochastic processes, lacking any form of consciousness or emotional capacity 17.
While the use of large language models in the medical field is growing, neurovascular research on their ability to predict patient outcomes remains limited. A retrospective analysis of clinical, neuroimaging, and procedure-related data involving 163 patients with acute ischemic stroke found that ChatGPT adequately predicted short-term functional mRS outcomes at 3-months after mechanical thrombectomy and was superior to existing risk scores 18.
Mortality and functional prognosis in aSAH is complex, with scales like Hunt and Hess and WFNS gauging risk based on initial assessments and traits but ignoring the effects of ending life support, which might bias outcomes 19. Furthermore, there´s growing concern that pessimistic views on severely injured patient´s recoveries might worsen outcomes, termed a “self-fulfilling prophecy” 20, 21. However, it is of paramount importance to scientifically validate these language models because patients and their relatives will potentially start putting trust in what conventional AI, like ChatGPT, predicts. Despite language model designers took steps to prevent these consultations by making sure that language models are not physicians and cannot give medical advices, such protocols can be bypassed by “jailbreak“ prompts, such as feigned scenarios as demonstrated in the present study 22.
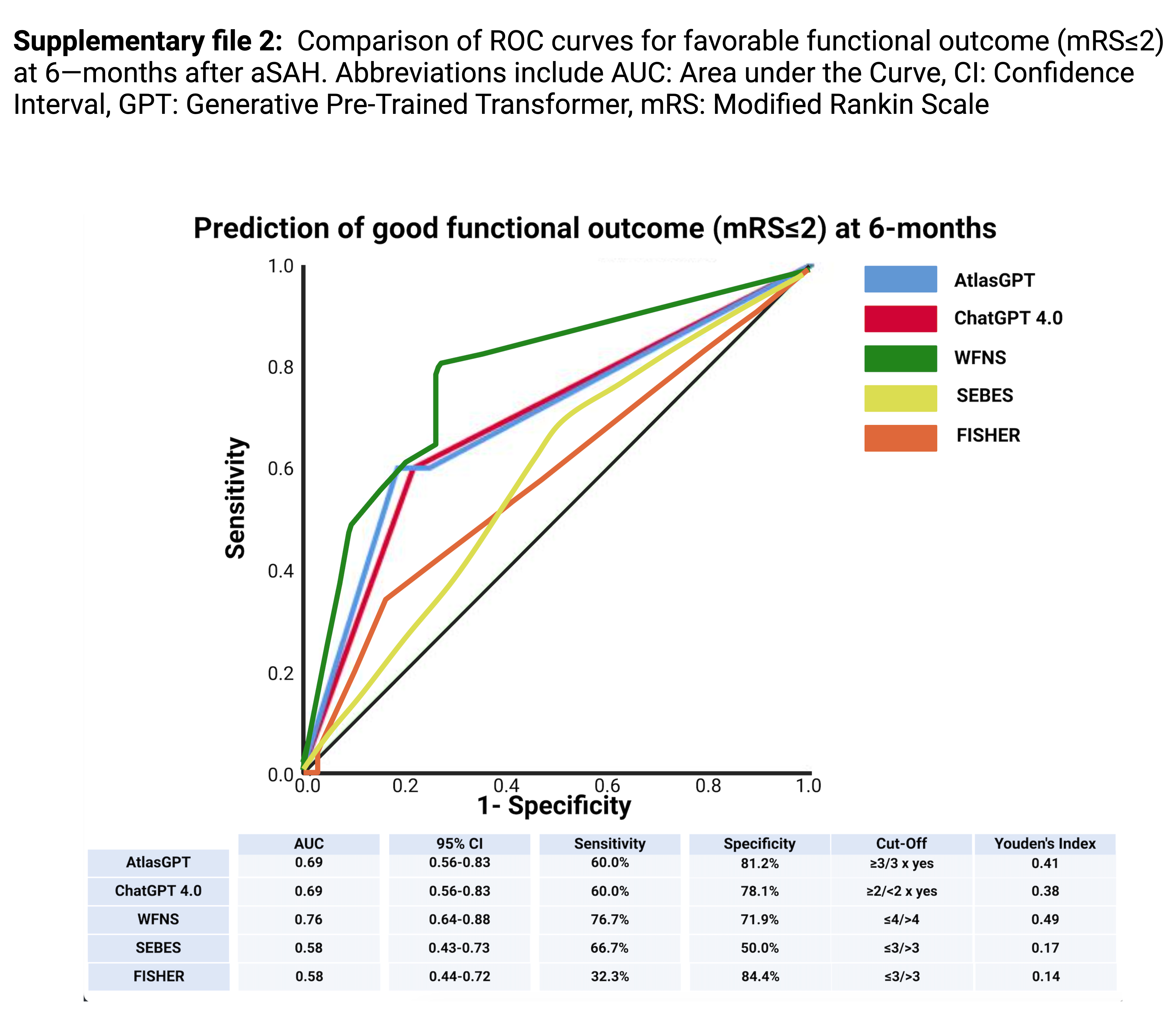
Physicians evaluating large language models should be also mindful of the “stochastic parrot” concept 23, 24. This principle highlights that due to its algorithmic nature, large language models lack comprehension of both the information it receives and the produced responses, merely replicating learned patterns and biases, including stereotypes and social disparities 25. These mechanisms might account for why the large language model´s performances in survival prediction and long-term neurological outcome prediction is comparable and not superior established clinical grading systems. This observation is consistent with findings from other research indicating similar levels of effectiveness in clinical or theoretical settings 26, 27. However, we found a superior role of a generated dialog describing baseline patient-, disease-, and procedure-specific aSAH patient characteristics which might facilitate the identification of those patients who will potentially undergo decompressive hemicraniectomy. Brain swelling and elevated ICP are established factors worsening outcomes after aSAH 28. Despite decompressive hemicraniectomy is a well-established procedure with high-level evidence for space-occupying stroke 29, the currently used language models and also AtlasGPT still have to rely on retrospective data. Further insights on the role of primary decompressive hemicraniectomy in aSAH and which patient will potentially benefit from this procedure might inform the randomized controlled PICASSO trial investigating decompressive hemicraniectomy in poor-grade (WFNS IV&V) aSAH patients 30.
Limitations
To our knowledge, this is the first investigation using large language models for predicting outcomes following aSAH with real-world patient data. It adopts a practical method focused on reproducibility and the integrity of data. Nonetheless, this study is not without its drawbacks.
First, there is the tendency of large language models to produce response variability which have to be addressed by repetitive approaches and trusting the mean values. Additionally, ChatGPT 4.0 was not specifically developed for medical use compared to AtlasGPT. Hence, the effectiveness and accuracy of ChatGPT 4.0 in addressing clinical issues has yet to be established. Finally, the present study represents a single-center cohort, which may limit their applicability to other settings or regions, underscoring the need for further studies across various environments to confirm the universality of these results. Finally, the present results have not been compared to a blinded experienced senior physician estimating the outcomes of the individual patients with the same baseline data.
{kind=link}
{kind=link}