Resource availability
Lead contact
Alvaro Jose Hahn Menacho, [email protected]
Materials availability
No materials were used in this study.
Data and code availability
The code required to reproduce the results presented in this study, and the results themselves, can be found in the following code repository: https://github.com/premise-community-scenarios/sweet_sure-2050-switzerland. The workflow requires premise and pathways, both open-sourced and installable via the Python package repository Pypi. However, the workflow also requires a valid license to the ecoinvent LCA database, which should be obtained from the Ecoinvent Association (https://ecoinvent.org/).
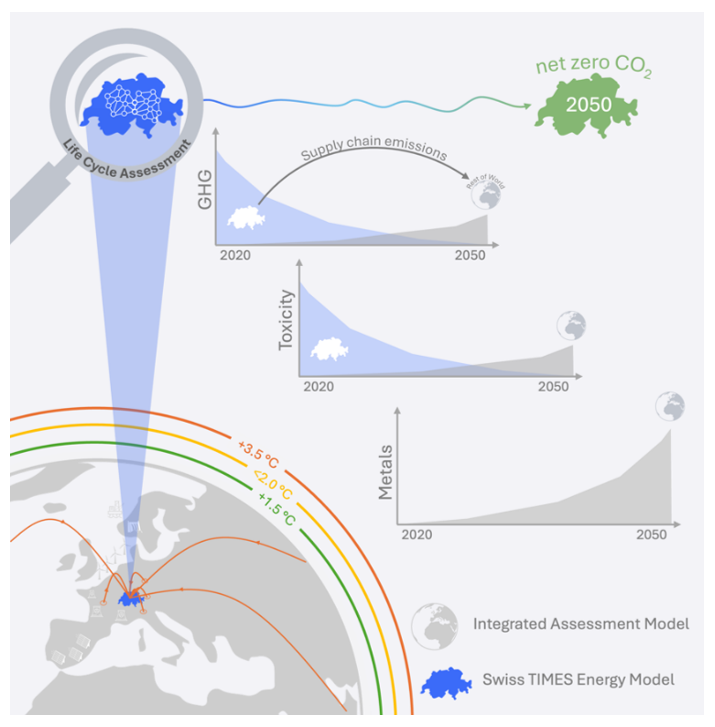
STEM modeling framework
The energy system modeling framework, upon which this work is built, consists of a large set of mathematical models orchestrated to provide a comprehensive view of the transformation of the Swiss economy and energy system towards achieving net zero GHG emissions by 2050. Detailed descriptions of the STEM model and the evaluated pathways can be found in Panos et al. (2023)38 and Panos et al. (2022)39, respectively. The pathways evaluated in this study correspond to the SURE Pathway Scenarios (SPS) 1 and 4. "SPS1: Team Sprint. Focus on Sustainability" aligns with the Net Zero scenario, while "SPS4: Walk & Talk. Current Trends and Policies" serves as the Baseline scenario. STEM includes only GHG from energy and industrial processes and not all GHG emissions (e.g., from agriculture). Regarding the transport sector, it follows the territorial approach. Thus, GHG emissions are accounted to the country of purchase. The detailed results used for this study can be found in the supplemental data repository.
The coupling of ESM and LCA
A prospective LCA approach is used to quantify environmental burdens of global supply chains in line with ESM and integrated assessment model scenarios. Using premise40, Swiss life cycle inventories are projected into the future by integrating results from STEM (i.e., Baseline and Net Zero scenarios), while processes in other world regions are projected using the REMIND integrated assessment model (IAM)17. Three REMIND scenarios are considered in this study: SSP2-NPi, SSP2-PkBudg1150, and SSP2-PkBudg500. The first scenario reflects the current trajectory based on existing national policies (NPi), under which global mean temperature could rise over 3.5 degrees Celsius by the end of the century. The second scenario limits global warming to approximately 2 degrees Celsius, with a global carbon budget of 1150 gigatons of CO2 for the entire century. The third scenario is intended to limit global warming to 1.5 degrees Celsius, with a global carbon budget of 500 gigatons of CO2. These scenarios capture different levels of ambition and risk associated with transitioning to a low-carbon future, providing a comprehensive range of potential pathways and their impacts41.
Integrating insights from ESM and IAM into LCA to extend present-day life-cycle inventories into the future has become a structured approach, establishing the methodological foundation for prospective LCA. This integration, initiated by Mendoza Beltran et al.42 and formalized by the Python library premise40, allows LCA to benefit from process and technology-specific forecasts in ESM and IAM, including learning curves, technological developments, and the evolution of electricity mixes and other dynamic parameters over time. Conversely, numerous efforts exist in the literature to perform LCA of ESM-based scenarios to gain a more comprehensive understanding of the sustainability of different energy system pathways8,10,43–46. However, these efforts are often fragmented and ad hoc, with varying scopes and methodologies, highlighting the need for a standardized approach applicable across different ESM, much like the early stages of prospective LCA. As was the case then, there is a need to consolidate the workflow, streamline the methodology, and develop tools that ensure reproducibility, computational efficiency, and methodological clarity.
In this study, we demonstrate the first application of the Python package pathways18 to systematically calculate the life-cycle impacts of an ESM scenario. This open-source library builds on the LCA framework brightway47. While we use premise together with scenarios from STEM, REMIND and the ecoinvent life-cycle inventory database48, pathways is model-agnostic. This ensures replicability, allowing the same workflow to be reproduced using different data sources and ESMs. The inputs necessary for pathways to perform the LCA calculations include a data package containing (1) a 'datapackage.json' metadata file describing the contents of the data package and (2) a 'mapping. yaml' file describing the links between the scenario variables and the LCA datasets; (3) the ESM scenario-based technosphere and biosphere LCA matrices for each time step as CSV files, produced by premise in this case; and (4) the ESM scenario data with production volumes for each time step as a CSV file. Files used in this study, based on the STEM scenarios, and necessary to produce the data package read by pathways, can be found at https://github.com/premise-community-scenarios/sweet_sure-2050-switzerland. pathways carries out calculations using bw2calc, the calculation module of brightway. Finally, some post-processing to address potential double-counting issues is performed. The tool returns the environmental impacts broken down by environmental indicator, product or service consumer, geographical location of consumer, time step, geographical origin of impacts, and life-cycle stage. See Data Availability to access the data package and the script used to produce the results presented in this study.
Mapping between STEM variables and life-cycle assessment
The mapping between final energy consumers in STEM and LCA datasets is described in the scenario data package's mapping file mapping.yaml found under the folder configuration_file in the online repository. The LCA datasets used for each final energy consumer of the STEM scenario are available in the file lci-sweet_sure.xlsx under the folder inventories in the online repository.
Functional units and Life cycle inventory (LCI)
As described above, each STEM variable representing a final energy consumer is matched with an LCA dataset. The LCA datasets that represent the consumption of final energy in vehicles include the supply of energy to the vehicle (e.g., gasoline, diesel, electricity, hydrogen) but also the storage component needed to store the energy on the road (e.g., fuel tank, hydrogen tank, battery) and the components needed to turn it into kinetic energy (e.g., internal combustion engine, electric motor). Using the kilometric lifetime of the vehicle and its tank-to-wheel energy consumption, we derive the fraction of the energy storage component needed per megajoule of energy consumed. The other vehicle components (e.g., glider, suspension, etc.) are left outside the energy system's scope.
For vehicles equipped with a battery (i.e., passenger cars, buses, trucks, two-wheelers, etc.), the “Mixed” scenario from Degen et al. (2023)49 is used. As shown in Fig. 6, it foresees the continued market deployment of lithium-ion batteries (i.e., Li-NMC and Li-LFP) until 2030 with a tendency toward nickel-rich and cobalt-poor chemistries (i.e., Li-NMC 955) and silicon-coated anodes (e.g., Li-NMC900-Si). After 2030, the scenario introduces post-lithium chemistries (e.g., solid-state, sodium-ion), which reach a 39% market share by 2040. We add the market shares of solid-state batteries to that of Sodium-ion batteries because of a lack of inventory data. For 2050, market shares for 2040 are used. Concurrently, the energy density of the cells also improves over time, as shown in Table 1.
Table 1
Current and projected battery energy density values.
| | Current | 2050 |
|---|
| Type | Specific energy density [kWh/kg cell] | Battery energy density [kWh/kg battery] | Source | Specific energy density [kWh/kg cell] | Battery energy density [kWh/kg battery] | Source |
| Li-ion, NMC111 | 0.18 | 0.13 | Hasselwander et al. (2023)50 | 0.2 | 0.15 | Maximum interval value for current energy density used as future mean |
| Li-ion, NMC523 | 0.2 | 0.15 | 0.22 | 0.16 |
| Li-ion, NMC622 | 0.24 | 0.18 | 0.26 | 0.19 |
| Li-ion, NMC811 | 0.28 | 0.2 | 0.34 | 0.24 |
| Li-ion, NMC955 | 0.34 | 0.24 | 0.38 | 0.27 |
| Li-ion, NCA | 0.28 | 0.2 | 0.34 | 0.24 |
| Li-ion, LFP | 0.16 | 0.13 | 0.22 | 0.18 |
| Li-ion, LiMn2O4 | 0.11 | 0.09 | Ecoinvent 3.1048 | 0.11 | 0.08 | No improvement considered |
| Li-ion, LTO | 0.05 | 0.03 | Wang et al. (2020)51 | 0.05 | 0.03 | No improvement considered |
| Li-sulfur, Li-S | 0.15 | 0.11 | Wickerts et al. (2023)52 | 0.34 | 0.26 | Duffner et al. (2021)53 |
| Li-oxygen, Li-O2 | 0.36 | 0.2 | Duffner et al. (2021)53 | 0.93 | 0.51 | Duffner et al. (2021)53 |
Other datasets representing the consumption of final energy by a specific consumer include the infrastructure needed to consume the energy (e.g., boiler, furnace, heat pump) and the supply of one megajoule of energy entering the conversion system. In all instances of combustion, the LCA dataset includes the combustion products. For example, modeling the consumption of one megajoule of wood pellets in an 80% efficient wood pellet stove is achieved by requiring the supply of 0.8 megajoule of heat from a wood pellet-fired stove.
As described above, the LCA datasets used for each final energy consumer of the STEM scenario are available in the file lci-sweet_sure.xlsx under the folder inventories in the online repository.
The ecoinvent LCA database v.3.10 (system model “allocation, cut-off by classification”) serves as the primary source for background inventory data, further modified by premise to align with a combination of global and Swiss scenarios. Complementing this, the premise library enriches the database by including inventories for emerging technologies and mining activities. Current LCI databases often exhibit gaps, particularly in representing critical raw materials, such as rhenium, rare earth oxides, and platinum group metals. Though used in small quantities, these materials play a pivotal role in various technologies and are frequently underrepresented or completely absent in existing inventories. Building on the work by Schlichenmaier and Naegler (2022)54, additional data is collected for electric and internal combustion engine vehicles, wind turbines, photovoltaic panels, concentrated solar power projects, nuclear plants, electric batteries, fuel cells, and electrolyzers.
Since metals are primarily traded globally, we model world markets for the various metals assessed. In these markets, the contribution of different mining and refining regions corresponds to their current market shares. Following this approach, the supply from different regions for a specific metal will be directly proportional to the country-level contributions to the global market. We derive these shares from various sources, mainly the British Geological Survey (BGS)55 and the United States Geological Survey (USGS)56, in addition to data from van den Brink et al. (2022)57 for antimony refining. For certain metals where data is accessible (e.g., lithium, cobalt), we incorporate projections from BloombergNEF regarding the development of future mining and refining projects to forecast the market shares’ evolution up to 203058. The metal markets also account for the average transport distances and modalities of the metal product from producer to consumer. This data is retrieved from The United Nations Conference on Trade and Development (UNCTAD)59.
These data and its implementation can be found in the premise online code repository (https://github.com/polca/premise). The data pertaining to the implementation of the STEM SPS scenarios into LCA, including the mapping between STEM technology variables and LCA datasets, are contained in the scenario online repository (https://github.com/premise-community-scenarios/sweet_sure-2050-switzerland).
Endogeneity and double-counting
In the context of combining LCA with ESM, double-counting needs addressing as ESM typically generate aggregate demand scenarios without distinguishing between intermediate and final energy demand. When these aggregate demands are used as inputs for LCA, there is a risk of counting the same resource use more than once. This is particularly problematic when assessing the environmental impacts of interconnected systems where the outputs of one process serve as inputs for another. If the demand for these materials is not carefully allocated between processes, the total environmental impact can be overestimated, resulting in misleading conclusions about the performance of the scenarios under analysis. Hence, the focus is on evaluating the total quantities yielded by the ESM's final output rather than the quantities provided by examining the supply chain as provided by LCA. To achieve this, the original life cycle inventory database is modified by zeroing out all regional energy inputs that are considered and potentially required by the energy system model throughout its life cycle, adhering to the rationale presented in Volkart et al. (2018)10. In this case, we focus on the inventories mapped as final energy providers. This approach is implemented in a systematic and reproducible manner, effectively isolating the quantities of interest and preventing the inflation of resource use that would otherwise occur due to supply chain overlaps. Consequently, this method enhances the accuracy of the life-cycle impact assessment.
However, the issue of double-counting is not completely eliminated and requires a more complex algorithm to be fully addressed throughout the LCA database. Indeed, double-counting persists because of how energy service demands in ESM, particularly global ones, are evaluated. Double-counting occurs when calculating energy service demands in ESM (e.g., tons of steel and chemicals) because mining and construction activities are also represented and included in an aggregated form. These calculations do not consider adjustments from a LCA perspective. Specifically, the tons of steel assumed in ESMs when calculating the energy used for production may not align with and have not been adjusted to reflect LCA calculations.
{kind=link}