A. Participants
The data from eighteen participants who were diagnosed with PD, implanted with bilateral STN DBS leads connected to an implanted investigative neurostimulator (Activa PC + S, Medtronic, PLC), and met the established criteria for dataset formation were used in our study. Participants were instructed to perform the experiment in the off-medication state. This involved stopping long-acting dopamine agonists at least 48 hours, dopamine agonists and controlled release carbidopa/levodopa at least 24 hours, and short acting medication at least 12 hours before testing. All participants gave written consent prior to the study. The study was approved by the Food and Drug Administration with an Investigational Device Exemption and by the Stanford University Institutional Review Board.
B. Experimental protocol
Participants performed SIP after DBS had been turned OFF for at least 15 minutes. To prevent any falls, participants wore safety jackets that were securely harnessed to the force plate system. In the beginning of the task, participants were first instructed to stand on two force plates that measure ground reaction force on each foot and were asked to remain as motionless as possible. Participants were then given a start cue and expected to alternatively lift their legs at their own pace for approximately 100 seconds (Fig. 1a). Lastly, participants were given a stop cue and were instructed to stop the movement after. The LFP signals from left and right STNs were recorded simultaneously with the measures from the two force plates.
C. Data acquisition and dataset formation criteria
Ground reaction forces were measured either using Neurocom (Neurocom Inc., Clackamas, OR, USA) or Bertec (Bertec Corporation, Columbus, OH, USA), which were measured at a sampling rate of 100 Hz and 1000 Hz from the two force plates, respectively. For the ground reaction forces measured at 1000 Hz sampling rate, the data were downsampled into 100 Hz to maintain consistency across data. The LFP signals were initially sampled with a sampling rate of 422 Hz and were downsampled to a 211 Hz sampling rate to train the deep learning model with lighter complexity. A pre-processing step was held on the retrieved force plate data by applying a low-pass filter of 2 Hz, in order to reduce jerky noises that are less likely to be related to gait. The data from the LFP signals were also band-pass filtered with ranges between 8 and 100 Hz to include a comprehensive range of frequency bands that may contain information associated with movement [29], [30].
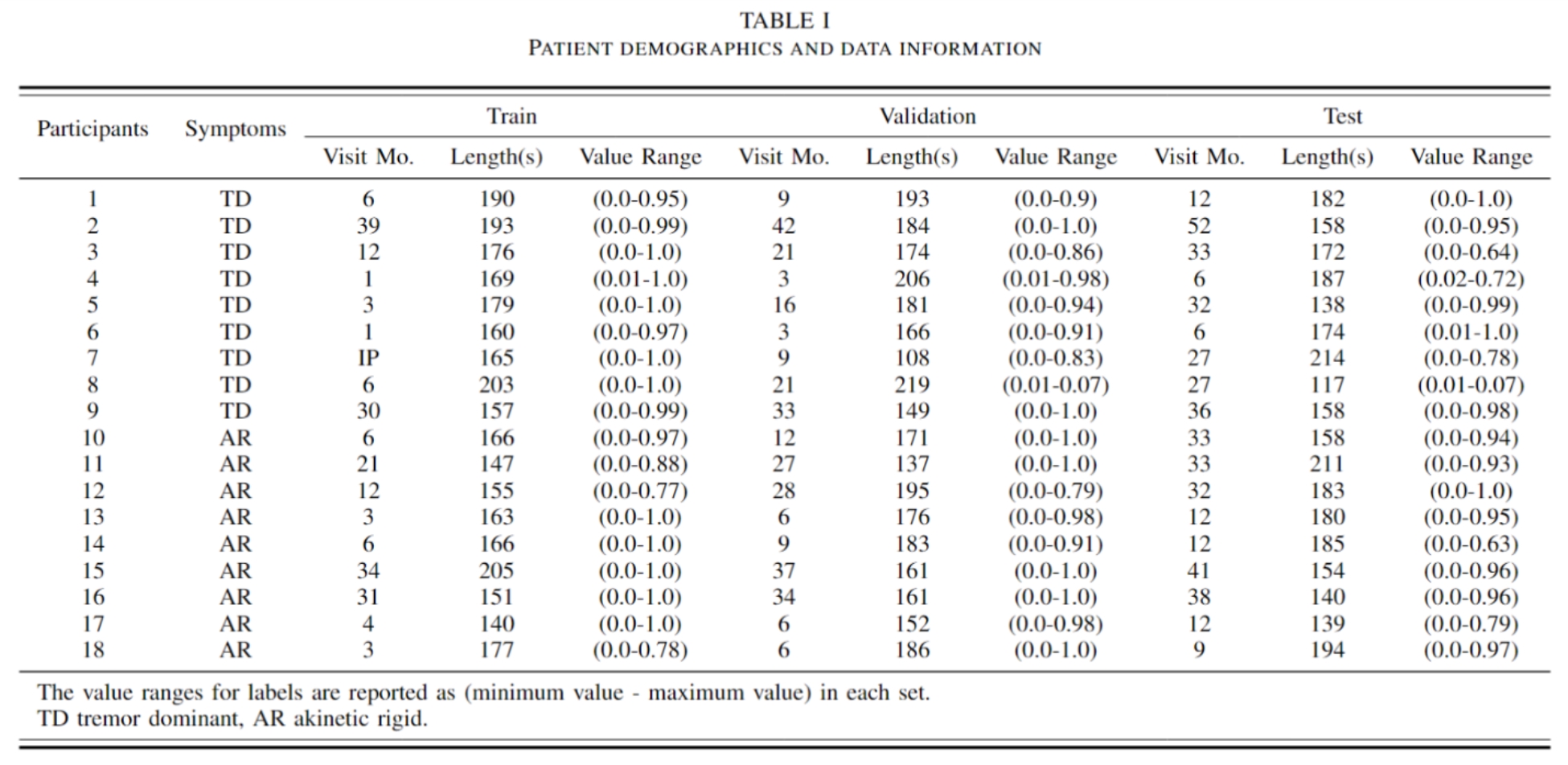
While most of the participants were involved in multiple visits performing the SIP task, we established criteria for the formation of datasets that were applied to each participant. Given that deep learning models require training, validation, and test datasets for training and evaluating the model, only the data from participants who completed the task at least three times on separate occasions were selected for this study. Specifically, the data acquired from the third most recent visit was used as a training set, the data from the second most recent visit was used as a validation set, and the data from the most recent visit was used as a test set for the model. This usage of visits in chronological order was done to limit the amount of data used for training the model while reflecting the actual usage scenario, where the model would be trained on past data while continuously receiving input of the most recent data for predictions. The datasets from each participant were formed in a way that their recording contacts remained consistent across the three visits. For participants who had their implantable pulse generators re-implanted between their visits, only the data collected before the re-implantation were included to maintain consistency of signal quality across datasets. The data from each visit was also visually inspected prior to the data formation to exclude visits that contained excessive noise not related to the task.
D. Gait quantification through weight shifts
The force plate data obtained from each task was first rescaled by dividing each data sample by the participant's weight, which was also retrieved from the two force plates when the participants remained motionless. This adjustment was done prior to quantifying weight shifts such that our measurement would be robust to variations in the participants' weight over different visits.
As participants distribute their weight over the two force plates when both feet are in contact, the measurements from the force plates are inversely proportional to each other. However, this correlation may not always hold true when one of the feet is off contact during the SIP task. Previous work had demonstrated that there may be cases where changes in force on the contacted force plate may still occur while participants tend to shift back towards the other force plate that is not yet in contact [28]. To take these patterns into consideration, the ground force samples from the plates were merged into a single value per time point by selecting the higher sample of the two, which disregarded samples with lower force measures including those of when the feet was off contact. Subsequently, samples from one of the force plates were mirrored symmetrically with respect to the value that signified half the patient's weight. Thus, samples having higher values would indicate more weight being placed on one force plate, while samples having lower value would represent more weight being distributed toward the other force plate. The change in force resulting from this merged outcome was quantified over a two-second time window to represent the amount of weight shift during that specific time interval (more details can be seen in Supplementary Fig. 1).
Considering that the task performance of each individual participant varies between visits and the performance also varies among participants, the data was normalized within each participant by mapping the maximum weight shift value of the two-second time window out of the three visits into 1, with a completely motionless state set as 0.
E. Deep learning model architecture
The architecture of our model is composed of four main blocks in a sequential manner: a feature extraction block, a feature squeeze and excitation block, a bi-directional long short-term memory (LSTM) block, and a regression block as shown in Fig. 1b. The model processes the bandpass filtered LFP signals to generate a single value outcome representing the predicted weight shift that the participant would have exhibited.
Feature extraction block
It has been shown that convolutional neural networks (CNNs) are capable of extracting oscillatory features [31], [32]. With inspiration from these previous approaches, our feature extraction block utilized 1-dimensional CNN with batch normalization, square activation function and average pooling to imitate the power measure computation from the inputted two band-pass filtered LFP signals. A 1-dimensional CNN was used in a depthwise manner, where each channel includes features from LFP of a single lead, such that the LFPs from the bilateral STNs are learned separately. Given the presence of aperiodic changes across datasets spanning extended time intervals, we implemented an element-wise division approach that utilizes half of the same-group features from the CNNs to divide the others. This division process was evolved with inspiration from previous studies that considered oscillatory features within specific frequency bands of interest in relation to more general or stabilized signal features [33]–[35]. Both the original numerators and resulting divided outcomes, denoted as original and relative features, were concatenated in a way that both types of features are considered for further model training.
Feature squeeze and excitation block
The feature squeeze and excitation block in our model is designed to rescale spectral features, emphasizing those with greater importance. As it is a widely known concept that rescaling features using an encoding and decoding approach such as squeeze and excitation networks or attention modules effectively highlight informative features [36], [37], the feature squeeze and excitation block of our model employs the similar concept. The outcome from the feature extraction block is processed in a way that the feature dimension is encoded and decoded back to its original shape for each length-dimension sample, with ReLU activation function used in between. Specifically, the oscillatory features are squeezed and excited for each temporal slice, with encoding and decoding parameters shared across temporal samples, resulting in an output of the same size as the shape before encoding. The resulting feature after further going through sigmoid activation was multiplied element-wise to the original output of the feature extraction block to rescale the features.
Bi-directional LSTM block
A three-layered stacked bi-directional LSTM was employed in our model to consider temporal changes in the LFP features within the provided time window. Recent findings suggest that beta burst duration, in extension to elevated beta power, also closely correlates with motor impairment [18], [23], [33]. Our bi-directional LSTM block was thus used to consider temporal oscillatory changes over time.
Regression block
The outcome after the bi-directional LSTM block was subsequently merged to finalize the regression model. By using a groupwise convolutional layer, features from the forward and backward LSTMs were first separately extracted. These features were then merged by sequentially going through convolutional and dense layers, and through ReLU activation function to complete our regression model that inputs 5-second LFP signals to output a single value weight shift prediction.
Note that our N2GNet did not utilize bias for the layers used in the model except for the layers in the feature squeeze and excitation block.
F. Model training
The overall algorithm was implemented with Python and the deep learning model was designed using Pytorch. The NVIDIA GeForce RTX 4090 GPU was used to train the model, and the adaptive moment algorithm (ADAM) optimization was used with a learning rate of 1e-5. We used the l1 loss function with a batch size of 16. The model was trained with a maximum epoch iteration set to 2000, and the early stopping was held whenever the model did not improve their validation loss for 100 epochs. The trained model from the epoch with the least l1 error rates computed using the validation dataset was selected to evaluate with the testing dataset (Fig. 1c).
The model for our experiment takes the most recent 5-second LFP signals of a particular time point as an input to predict the weight shift over the last 2 seconds. The datasets for training, validation, and testing are formed in a way that they include the last 5-second LFP signals and a single label representing the last 2-second of weight shift at every 0.1 second stride within each task duration. The model was also trained and evaluated in a subject-dependent manner, where the model was trained, validated and tested separately on each participant.
G. Evaluation and analysis
The length of data varied across tasks and the weight shifts performed by participants, which were rescaled to within the range of 0 and 1 and used as dataset labels, were not uniformly distributed within each task. Taking into account such factors, both mean absolute error (MAE) and mean squared error (MSE), which are two commonly used evaluation metrics for assessing regression performance in machine learning models [27], were computed on both validation and test datasets. This was done in order to provide more comprehensive insights into the performance of the models evaluated in this study, and also with consideration that both validation and test sets were obtained from visits that occurred considerably later than the visits from which the training data were collected. We also conducted correlation analysis using Kendall tau coefficient [38], a non-parametric statistic to measure the association between the two variables, to quantify correlations between the model's predicted results and the weight shifts. Correlations of each 2-second average beta power computed from the LFPs of the two leads with respect to the weight shifts were also quantified and compared with those between N2GNet's predictions and the weight shifts to explore the benefits of using N2GNet over beta power.
A model ablation study, a commonly used analysis method for deep learning to investigate how each block composing the final model contributed to its performance [39], [40], was conducted with our N2GNet. A total of seven other models derived from our N2GNet were thus designed, assessed, and compared. The models were named as FExt-Div, FExt-Div + SE, FExt-Div + Bi, FExt-Div + SE + BI, FExt, FExt + SE, and FExt + Bi, depending on which parts of the original N2GNet model were used or neglected (details of the model designs can be seen in Supplementary Fig. 2).
To explore which frequency band signals had more impact on the trained model, we measured the variation ratio of the model’s output concerning different frequency band ranges. Specifically, the following procedure was conducted on each participant’s model to investigate which frequency bands had more influence over other bands:
-
The LFP data from the training set was band-pass filtered with each frequency band of interest, and were inputted to the model.
-
The model's outcomes prior to the last ReLU activation from the regression block were hooked for each frequency band of interest, and the variance of these outcomes from the same frequency band of interest were measured.
-
Variance measures from different frequency bands were normalized as a variance ratio such that its total resulting from all frequency bands would equal to a value of 1 on each participant.
With the models used in our study producing a single value per input, the variance ratio derived from the resulting values provides insights into which frequency band signals were more influential in producing the final outcome.
The variance ratio in our study were measured using six different frequency bands: delta and theta (∼8 Hz), alpha (8–13 Hz), low-beta (13–20 Hz), high-beta (20–36 Hz), low-gamma (36–70 Hz) and high-gamma (70∼ Hz).
H. Statistical analysis
For statistical comparisons involving two groups with independent variables, we utilized the Mann-Whitney U test. We also utilized the Wilcoxon signed-rank test for statistical comparisons that involved paired samples. A Kendall tau correlation coefficient analysis was used to quantify the association between two data measures. These statistical tests were performed considering that the number of participants is relatively small (n = 9 for both TD and AR groups, and a total of 18 PD participants), and the non-parametric tests do not assume normal distribution of the data. We reported measures with p-values below a threshold of 0.05 as significant for Mann-Whitney U tests. A threshold of 0.025 (0.05/2) was considered significant for p-values from the Wilcoxon signed-rank tests considering a Bonferroni correction for the two tests conducted, one from validation sets and the other from test sets.
{kind=link}