2.2 Active chemical composition of FS
The active components and target proteins of finger citron were selected from the Traditional Chinese Medicine Systems Pharmacology Database and Analysis Platform (TCMSP, http://lsp.nwu.edu.cn/tcmsp.php) which is a unique platform for the analysis of active ingredients of Chinese herbal medicine and their mutual effect [21]. Based on the ADME (absorption, distribution, metabolism, and excretion) model[22], We obtained the 4 key active components of finger citron when oral bioavailability (OB) ≥ 30% [23]and drug likeness (DL) ≥ 0.18[24], Meanwhile, other 21 components were replenished from relevant literature. The species of target proteins were set to “Homo sapiens”,and the predicted target proteins were normalized using the official symbol of their names and submitted to the UniProt protein sequence resource (http://www.uniprot.org/),and the whole gene information including gene name, gene ID, gene symbol was obtained.
2.3 Related targets of obesity and prediction of potential targets of FS against obesity
Using “obesity,” “fat,” and “adiposis” as keywords, we conducted searches on the GeneCards (https://www.genecards.org), Online Mendelian Inheritance in Man (OMIM, http://www.omim.org), DisGeNET (https://www.disgenet.org), and DrugBank (https://www.drugbank.ca)[25] databases for obesity-associated target proteins. We combined the search results from each database to eliminate duplicate results.
2.4 Identifying obesity-related targets in FS
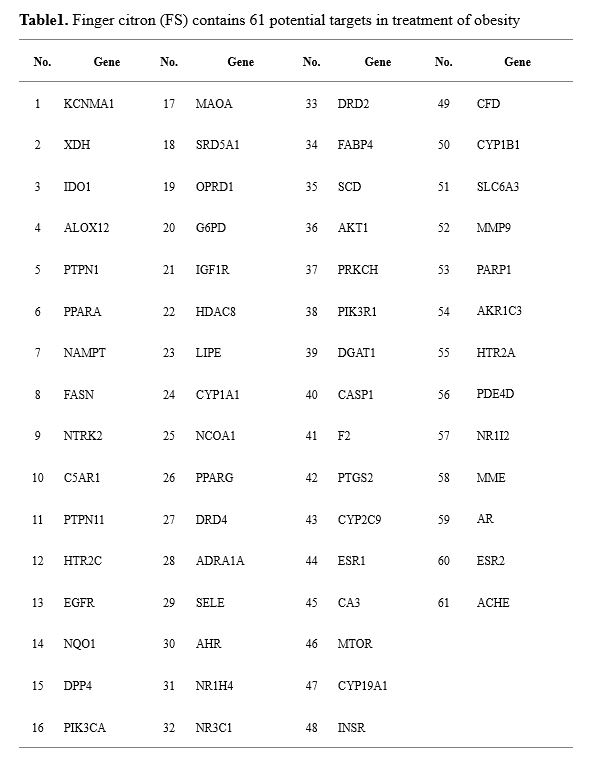
The obesity-related targets of finger citron were imported into the VENN (http://bioinformatics.psb.ugent.be/webtools/Venn/) online tool to generate a Venn diagram. Obesity-related genes targeted by FS were determined, and a database of target genes of compounds for treating obesity was constructed by extracting the intersecting target genes. Components and disease target genes unrelated to obesity were removed. Finally, the disease target genes of FS were obtained, and a common target database was established.
2.5 Network construction of the protein interaction
We using the STRING11.0 (https://string-db.org) platform to further elucidate the interactions of the common target genes. The protein species was set to “Homo sapiens.” The minimum interaction score was set to “Medium Confidence (0.400).”The rest are set to default values. Enhanced interaction between targets while ensuring a positive rate, exported the protein-protein interactions (PPI) network after removing the discrete genes. Finally, the PPI network graph was visualized. We collected the targets of each ingredient and the repeating targets were removed to obtain the FS related targets. The PPI network diagram shown the common key targets of FS and obesity.
2.6 Construction of the network modules and analysis
CytoScape3.7.1 software was used to construct a component-disease, target-path network diagram to analyze network topology parameters, including degree of degree, betweenness, and closeness of active components and targets. We determined the core target and the main active ingredient of FS that exerts the anti-obesity effect according to the network topology parameters.
2.7 Pathway enrichment analysis
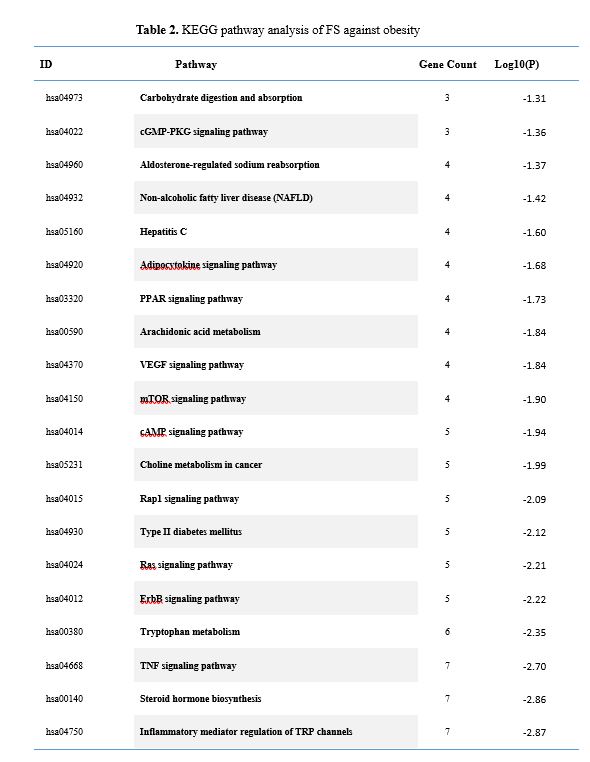
The Database for Annotation, Visualization, and Integrated Discovery (DAVID) Bioinformatics Resources 6.8 platform (https://david.ncifcrf.gov) was used to perform enrichment analysis on the biological functions and molecular signaling pathways of the common targets identified. After the PPI network was successfully constructed, co-targets were imported into R software and the cluster profile. Bio-conductor package was used to perform the GO and KEGG enrichment analysis, to obtain the biological processes, cellular components, molecular function and key signaling pathways. Only functional annotations with enrichment p values smaller than 0.05 were chosen for further analysis.
{kind=link}
{kind=link}
{kind=link}